Note
-
Download Jupyter notebook:
https://docs.doubleml.org/stable/examples/py_double_ml_lplr.ipynb.
Python: Log-Odds Effects for Logistic PLR models#
In this simple example, we illustrate how the DoubleML package can be used to estimate the changes in log-odds due to treatment in a logistic partial linear regression DoubleMLLPLR model.
[1]:
import numpy as np
import scipy
import matplotlib.pyplot as plt
import doubleml as dml
from doubleml.plm.datasets import make_lplr_LZZ2020
Data#
We define a data generating process to create synthetic data to compare the estimates to the true effect. The data generating process is adapted and extended from Liu et al. (2020).
The documentation of the data generating process can be found API Reference.
The data generation process supports both binary and continuous treatments. In this example we consider a continuous treatment effect. Both the treatment assignment (if binary) and the outcome variable balancing can be can be adjusted.
[2]:
np.random.seed(42)
data = make_lplr_LZZ2020(n_obs=1000, dim_x=20, alpha=0.5, treatment="continuous")
print(data)
================== DoubleMLData Object ==================
------------------ Data summary ------------------
Outcome variable: y
Treatment variable(s): ['d']
Covariates: ['X1', 'X2', 'X3', 'X4', 'X5', 'X6', 'X7', 'X8', 'X9', 'X10', 'X11', 'X12', 'X13', 'X14', 'X15', 'X16', 'X17', 'X18', 'X19', 'X20']
Instrument variable(s): None
No. Observations: 1000
------------------ DataFrame info ------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Columns: 23 entries, X1 to p
dtypes: float64(23)
memory usage: 179.8 KB
Model#
The logistic partial linear regression (LPLR) model is specified as follows:
where \(Y\) is the binary outcome variable and \(D\) is the policy variable of interest. The vector \(X = (X_1, \ldots, X_p)\) consists of other confounding covariates and \(\text{expit}\) is the logistic link function
The log-odds of the treated versus the untreated is modelled as a partial linear model. The estimated coefficient \(\beta_0\) can be interpreted as the change in log-odds due to a one unit increase in the treatment variable \(D\), holding all other covariates constant.
Next, define the learners for the nuisance functions and fit the LPLR Model. The correct type of learner (regressor or classifier) must be used for each nuisance function.
ml_Mis a model of the outcome. Here, since the outcome is binary, we use a classifier.ml_tis a model of the log-odds. This must always be a regressor.ml_mis a model of the treatment. Here, since the treatment is continuous, we use a regressor. In the case of a binary treatment, a classifier must be used.
[4]:
# First stage estimation
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
randomForest_reg = RandomForestRegressor(min_samples_leaf=5)
randomForest_class = RandomForestClassifier(min_samples_leaf=5)
np.random.seed(4242)
dml_lplr = dml.DoubleMLLPLR(data,
ml_M=randomForest_class,
ml_t=randomForest_reg,
ml_m=randomForest_reg,
n_folds=5)
print("Training LPLR Model")
dml_lplr.fit()
print(dml_lplr.summary)
Training LPLR Model
coef std err t P>|t| 2.5 % 97.5 %
d 0.347501 0.090728 3.830142 0.000128 0.169677 0.525324
Visualizations#
We can plot the estimated probabilites from the nuisance function and compare with the observed outcome. We observe that there is good overlap of observed outcomes and accross the range of treatment variable D. Further, the probability estimate from the confounders is independent of the treatment variable D, as expected.
[9]:
probability = dml_lplr.psi_elements["r_hat"].squeeze()
probability = scipy.special.expit(probability)
plt.figure(figsize=(10, 6))
plt.scatter(dml_lplr.psi_elements["d"].squeeze(),
dml_lplr.psi_elements["y"].squeeze(),
alpha=0.6, s=30, label="Observed Outcome")
plt.scatter(dml_lplr.psi_elements["d"].squeeze(),
probability,
alpha=0.6, s=30, label="Probability Estimate from confounders")
plt.legend(loc="upper center", bbox_to_anchor=(0.5, -0.15), ncol=2, frameon=True, shadow=True)
plt.xlabel("Treatment variable D", fontsize=12)
plt.ylabel("Outcome / Probability", fontsize=12)
plt.title("Estimated Outcome Probabilities from Confounding", fontsize=14, pad=15)
plt.grid(True, alpha=0.3, linestyle='--')
plt.tight_layout()
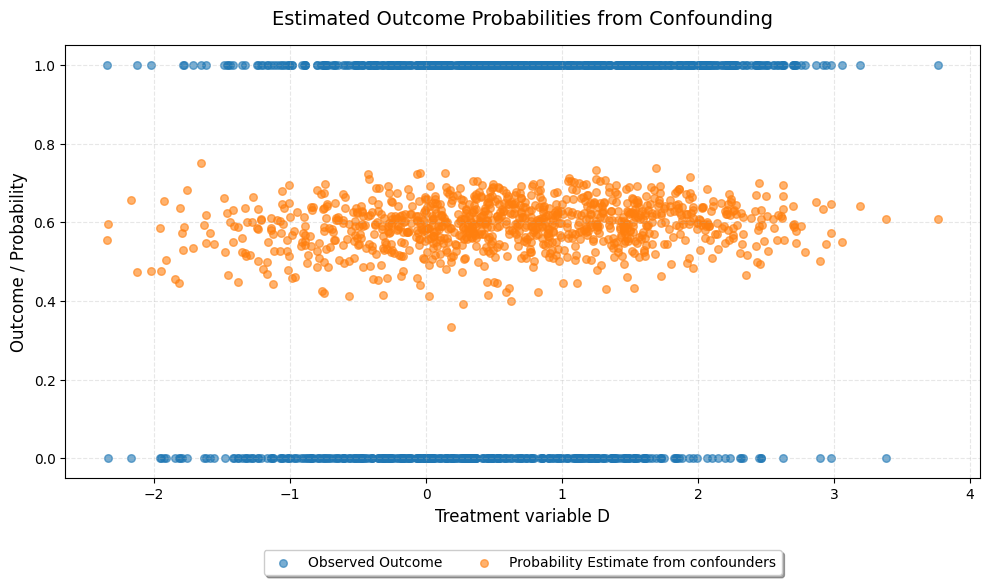
Next, we look at the estimated probability only based on the treatment assignment, as well as the overall probability estimate of the LPLR model.
[8]:
x = np.arange(-4, 4.1, 0.1)
probability_from_treatment = x* dml_lplr.coef.squeeze()
probability_from_treatment = scipy.special.expit(probability_from_treatment)
joint_probability = dml_lplr.psi_elements["r_hat"].squeeze() + dml_lplr.psi_elements["d"].squeeze() * dml_lplr.coef.squeeze()
joint_probability = scipy.special.expit(joint_probability)
plt.figure(figsize=(10, 6))
plt.scatter(dml_lplr.psi_elements["d"].squeeze(),
dml_lplr.psi_elements["y"].squeeze(),
alpha=0.6, s=30, label="Observed Outcome")
plt.scatter(x, probability_from_treatment,
alpha=0.6, s=30, label="Probability Estimate from Treatment Effect only")
plt.scatter(dml_lplr.psi_elements["d"].squeeze(),
joint_probability,
alpha=0.6, s=30, label="Model Probability Estimate")
plt.legend(loc="upper center", bbox_to_anchor=(0.5, -0.15), ncol=3, frameon=True, shadow=True)
plt.xlabel("Treatment variable D", fontsize=12)
plt.ylabel("Outcome / Probability", fontsize=12)
plt.title("Estimated Outcome Probabilities from Treatment and Confounding", fontsize=14, pad=15)
plt.grid(True, alpha=0.3, linestyle='--')
plt.tight_layout()
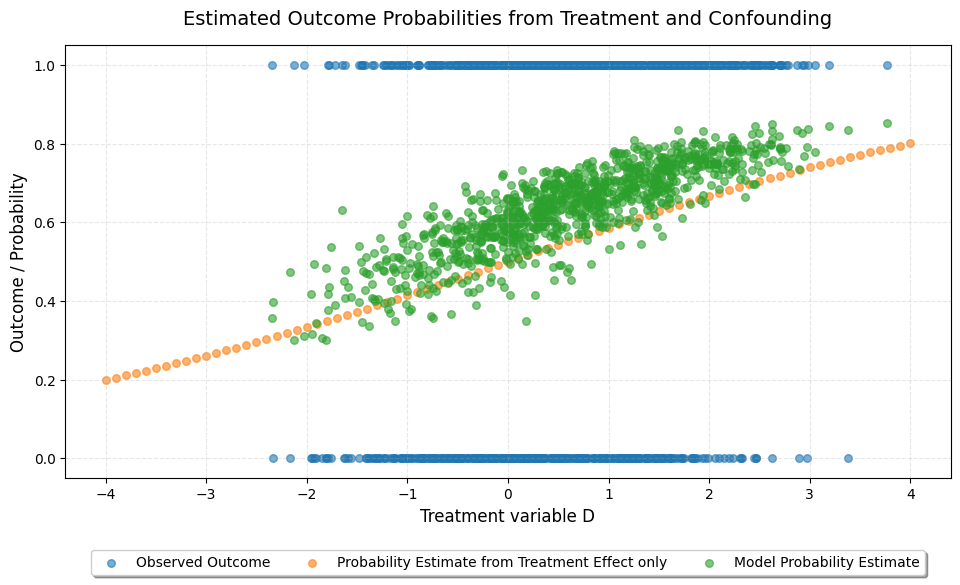
Note: The line and scatter are not perfectly aligned as the expit function is not additive. However, we can see that the treatment effect shifts the overall probability estimate up or down depending on the value of D.