Note
-
Download Jupyter notebook:
https://docs.doubleml.org/stable/examples/py_double_ml_gate_plr.ipynb.
Python: Group Average Treatment Effects (GATEs) for PLR models#
In this simple example, we illustrate how the DoubleML package can be used to estimate group average treatment effects in the DoubleMLPLR model.
[1]:
import numpy as np
import pandas as pd
import doubleml as dml
from doubleml.irm.datasets import make_heterogeneous_data
Data#
We define a data generating process to create synthetic data to compare the estimates to the true effect. The data generating process is based on the Monte Carlo simulation from Oprescu et al. (2019).
The documentation of the data generating process can be found here. In this example the true effect depends only the first covariate \(X_0\) and takes the following form
[2]:
np.random.seed(42)
data_dict = make_heterogeneous_data(
n_obs=500,
p=10,
support_size=5,
n_x=1,
)
data = data_dict['data']
print(data.head())
y d X_0 X_1 X_2 X_3 X_4 \
0 -1.543764 -0.605195 0.925248 0.180575 0.567945 0.915488 0.033946
1 0.463766 0.056499 0.474214 0.862043 0.844549 0.319100 0.828915
2 5.946406 0.920337 0.696289 0.339875 0.724767 0.065356 0.315290
3 8.994937 1.356167 0.615863 0.232959 0.024401 0.870099 0.021269
4 0.254038 -0.190921 0.350712 0.767188 0.401931 0.479876 0.627505
X_5 X_6 X_7 X_8 X_9
0 0.697420 0.297349 0.924396 0.971058 0.944266
1 0.037008 0.596270 0.230009 0.120567 0.076953
2 0.539491 0.790723 0.318753 0.625891 0.885978
3 0.874702 0.528937 0.939068 0.798783 0.997934
4 0.873677 0.984083 0.768273 0.417767 0.421357
The generated dictionary also contains the true individual effects saved in the key effects.
[3]:
ite = data_dict['effects']
print(ite[:5])
[4.770944 5.4235839 5.07202564 5.30917769 4.97441062]
The goal is to estimate the average treatment effect for different groups based on the covariate \(X_0\). The groups can be specified as DataFrame with boolean columns. We consider the following three groups
[4]:
groups = pd.DataFrame(
np.column_stack((data['X_0'] <= 0.3,
(data['X_0'] > 0.3) & (data['X_0'] <= 0.7),
data['X_0'] > 0.7)),
columns=['Group 1', 'Group 2', 'Group 3'])
print(groups.head())
Group 1 Group 2 Group 3
0 False False True
1 False True False
2 False True False
3 False True False
4 False True False
The true effects (still including sampling uncertainty) are given by
[5]:
true_effects = [ite[groups[group]].mean() for group in groups.columns]
print(true_effects)
[np.float64(2.906716732639898), np.float64(5.223485956098176), np.float64(4.827938162750831)]
Partially Linear Regression Model (PLR)#
The first step is to fit a DoubleML PLR Model to the data.
[6]:
data_dml_base = dml.DoubleMLData(
data,
y_col='y',
d_cols='d'
)
[7]:
# First stage estimation
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
ml_l = RandomForestRegressor(n_estimators=500)
ml_m = RandomForestRegressor(n_estimators=500)
np.random.seed(42)
dml_plr = dml.DoubleMLPLR(data_dml_base,
ml_l=ml_l,
ml_m=ml_m,
n_folds=5)
print("Training PLR Model")
dml_plr.fit()
print(dml_plr.summary)
Training PLR Model
coef std err t P>|t| 2.5 % 97.5 %
d 4.43883 0.088282 50.280196 0.0 4.2658 4.611859
Group Average Treatment Effects (GATEs)#
To calculate GATEs just call the gate() method and supply the DataFrame with the group definitions and the level (with default of 0.95). Remark that for straightforward interpretation of the GATEs the groups should be mutually exclusive.
[8]:
gate = dml_plr.gate(groups=groups)
print(gate.confint(level=0.95))
2.5 % effect 97.5 %
Group 1 2.602079 2.942139 3.282200
Group 2 4.888775 5.048308 5.207840
Group 3 4.660320 4.856404 5.052488
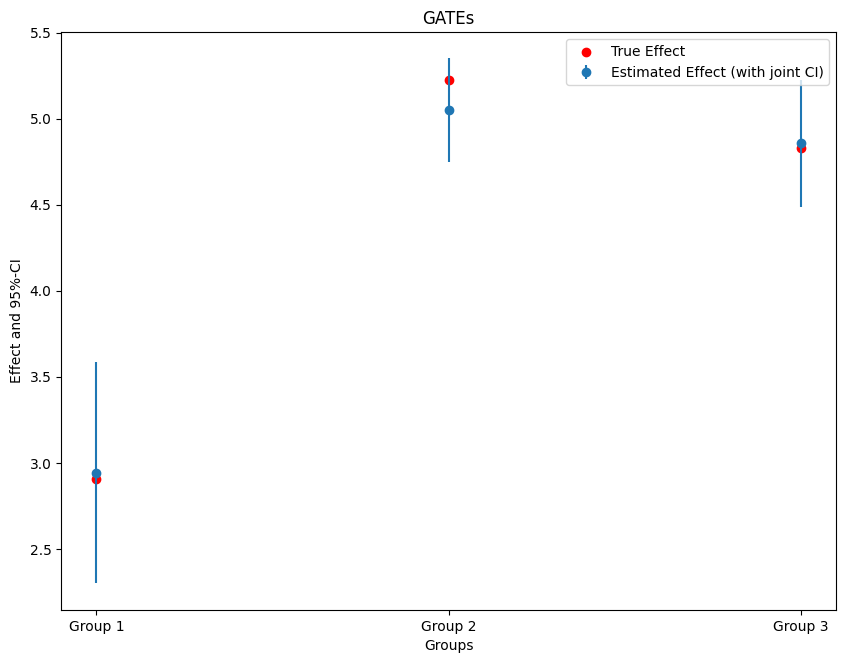
The confidence intervals above are point-wise, but by setting the option joint and providing a number of bootstrap repetitions n_rep_boot.
[9]:
ci = gate.confint(level=0.95, joint=True, n_rep_boot=1000)
print(ci)
2.5 % effect 97.5 %
Group 1 2.299537 2.942139 3.584742
Group 2 4.746843 5.048308 5.349772
Group 3 4.485871 4.856404 5.226938
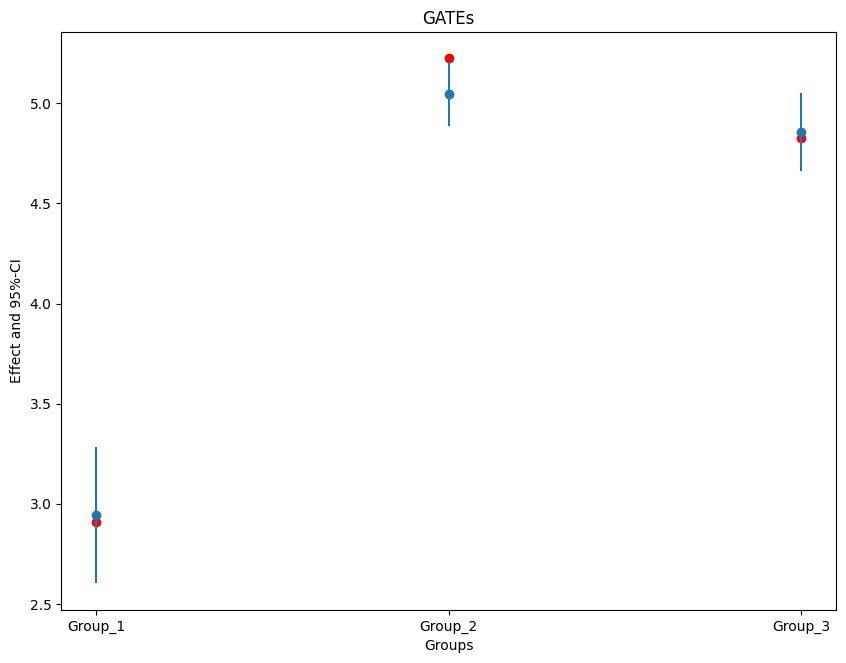
Finally, let us plot the estimates together with the true effect within each group.
[10]:
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = 10., 7.5
errors = np.full((2, ci.shape[0]), np.nan)
errors[0, :] = ci['effect'] - ci['2.5 %']
errors[1, :] = ci['97.5 %'] - ci['effect']
plt.errorbar(ci.index, ci.effect, fmt='o', yerr=errors, label='Estimated Effect (with joint CI)')
#add true effect
ax = plt.subplot(1, 1, 1)
ax.scatter(x=['Group 1', 'Group 2', 'Group 3'], y=true_effects, c='red', label='True Effect')
plt.title('GATEs')
plt.xlabel('Groups')
plt.legend()
_ = plt.ylabel('Effect and 95%-CI')
It is also possible to supply disjoint groups as a single vector (still as a data frame). Remark the slightly different name.
[11]:
groups = pd.DataFrame(columns=['Group'], index=range(data['X_0'].shape[0]), dtype=str)
for i, x_i in enumerate(data['X_0']):
if x_i <= 0.3:
groups.loc[i, 'Group'] = '1'
elif (x_i > 0.3) & (x_i <= 0.7):
groups.loc[i, 'Group'] = '2'
else:
groups.loc[i, 'Group'] = '3'
print(groups.head())
Group
0 3
1 2
2 2
3 2
4 2
This time lets consider pointwise confidence intervals.
[12]:
gate = dml_plr.gate(groups=groups)
ci = gate.confint()
print(ci)
2.5 % effect 97.5 %
Group_1 2.602079 2.942139 3.282200
Group_2 4.888775 5.048308 5.207840
Group_3 4.660320 4.856404 5.052488
The coefficients of the best linear predictor can be seen via the summary (the values can be accessed through the underlying model .blp_model).
[13]:
print(gate.summary)
coef std err t P>|t| [0.025 0.975]
Group_1 2.942139 0.173504 16.957229 1.701841e-64 2.602079 3.282200
Group_2 5.048308 0.081396 62.021690 0.000000e+00 4.888775 5.207840
Group_3 4.856404 0.100044 48.542446 0.000000e+00 4.660320 5.052488
Remark that the confidence intervals in the summary are slightly smaller, since they are not based on the White’s heteroskedasticity robus standard errors.
[14]:
errors = np.full((2, ci.shape[0]), np.nan)
errors[0, :] = ci['effect'] - ci['2.5 %']
errors[1, :] = ci['97.5 %'] - ci['effect']
#add true effect
ax = plt.subplot(1, 1, 1)
ax.scatter(x=['Group_1', 'Group_2', 'Group_3'], y=true_effects, c='red', label='True Effect')
plt.errorbar(ci.index, ci.effect, fmt='o', yerr=errors)
plt.title('GATEs')
plt.xlabel('Groups')
_ = plt.ylabel('Effect and 95%-CI')