Note
-
Download Jupyter notebook:
https://docs.doubleml.org/stable/examples/py_double_ml_pq.ipynb.
Python: Potential Quantiles and Quantile Treatment Effects#
In this example, we illustrate how the DoubleML package can be used to estimate (local) potential quantiles and (local) quantile treatment effects. The estimation is based on Kallus et al. (2019).
Potential Quantiles (PQs)#
At first, we will start with the estimation of the quantiles of the potential outcomes.
Data#
We define a data generating process to create synthetic data to compare the estimates to the true effect.
[1]:
import numpy as np
import pandas as pd
import doubleml as dml
import multiprocessing
from lightgbm import LGBMClassifier
The data is generated as a location-scale model with
where \(X_i\sim\mathcal{U}[-1,1]^{p}\) and \(\varepsilon_i \sim \mathcal{N}(0,1)\). Further, the location and scale are determined according to the following functions
and the treatment takes the following form
with \(\epsilon_i \sim \mathcal{N}(0,1)\).
[2]:
def f_loc(D, X):
loc = 0.5*D + 2*D*X[:,4] + 2.0*(X[:,1] > 0.1) - 1.7*(X[:,0] * X[:,2] > 0) - 3*X[:,3]
return loc
def f_scale(D, X):
scale = np.sqrt(0.5*D + 0.3*D*X[:,1] + 2)
return scale
def dgp(n=200, p=5):
X = np.random.uniform(-1,1,size=[n,p])
D = ((X[:,1 ] - X[:,3] + 1.5*(X[:,0] > 0) + np.random.normal(size=n)) > 0)*1.0
epsilon = np.random.normal(size=n)
Y = f_loc(D, X) + f_scale(D, X)*epsilon
return Y, X, D, epsilon
We can calculate the true potential quantile analytically or through simulations. Here, we will just approximate the true potential quantile for a range of quantiles.
[3]:
tau_vec = np.arange(0.1,0.95,0.05)
n_true = int(10e+6)
_, X_true, _, epsilon_true = dgp(n=n_true)
D1 = np.ones(n_true)
D0 = np.zeros(n_true)
Y1 = f_loc(D1, X_true) + f_scale(D1, X_true)*epsilon_true
Y0 = f_loc(D0, X_true) + f_scale(D0, X_true)*epsilon_true
Y1_quant = np.quantile(Y1, q=tau_vec)
Y0_quant = np.quantile(Y0, q=tau_vec)
print(f'Potential Quantile Y(0): {Y0_quant}')
print(f'Potential Quantile Y(1): {Y1_quant}')
Potential Quantile Y(0): [-3.33065771 -2.7142787 -2.2114026 -1.77261209 -1.37433503 -1.00032016
-0.64362337 -0.29675887 0.04608822 0.38898864 0.73569431 1.09245337
1.46598119 1.86610467 2.30628774 2.81128199 3.43361991]
Potential Quantile Y(1): [-3.23801203 -2.54010127 -1.97499195 -1.48353114 -1.03783666 -0.62195343
-0.22563538 0.15946647 0.53849791 0.91771387 1.30229388 1.70007159
2.11789998 2.56670073 3.06397789 3.63817859 4.35053317]
Let us generate \(n=5000\) observations and convert them to a DoubleMLData object.
[4]:
n = 5000
np.random.seed(42)
Y, X, D, _ = dgp(n=n)
obj_dml_data = dml.DoubleMLData.from_arrays(X, Y, D)
Potential Quantile Estimation#
Next, we can initialize our two machine learning algorithms to train the different nuisance elements. Then we can initialize the DoubleMLPQ objects and call fit() to estimate the relevant parameters. To obtain confidence intervals, we can use the confint() method.
[5]:
ml_m = LGBMClassifier(n_estimators=300, learning_rate=0.05, num_leaves=10, verbose=-1, n_jobs=1)
ml_g = LGBMClassifier(n_estimators=300, learning_rate=0.05, num_leaves=10, verbose=-1, n_jobs=1)
PQ_0 = np.full((len(tau_vec)), np.nan)
PQ_1 = np.full((len(tau_vec)), np.nan)
ci_PQ_0 = np.full((len(tau_vec),2), np.nan)
ci_PQ_1 = np.full((len(tau_vec),2), np.nan)
for idx_tau, tau in enumerate(tau_vec):
print(f'Quantile: {tau}')
dml_PQ_0 = dml.DoubleMLPQ(obj_dml_data,
ml_g, ml_m,
quantile=tau,
treatment=0,
n_folds=5)
dml_PQ_1 = dml.DoubleMLPQ(obj_dml_data,
ml_g, ml_m,
quantile=tau,
treatment=1,
n_folds=5)
dml_PQ_0.fit()
dml_PQ_1.fit()
ci_PQ_0[idx_tau, :] = dml_PQ_0.confint(level=0.95).to_numpy()
ci_PQ_1[idx_tau, :] = dml_PQ_1.confint(level=0.95).to_numpy()
PQ_0[idx_tau] = dml_PQ_0.coef.squeeze()
PQ_1[idx_tau] = dml_PQ_1.coef.squeeze()
Quantile: 0.1
Quantile: 0.15000000000000002
Quantile: 0.20000000000000004
Quantile: 0.25000000000000006
Quantile: 0.30000000000000004
Quantile: 0.3500000000000001
Quantile: 0.40000000000000013
Quantile: 0.45000000000000007
Quantile: 0.5000000000000001
Quantile: 0.5500000000000002
Quantile: 0.6000000000000002
Quantile: 0.6500000000000001
Quantile: 0.7000000000000002
Quantile: 0.7500000000000002
Quantile: 0.8000000000000002
Quantile: 0.8500000000000002
Quantile: 0.9000000000000002
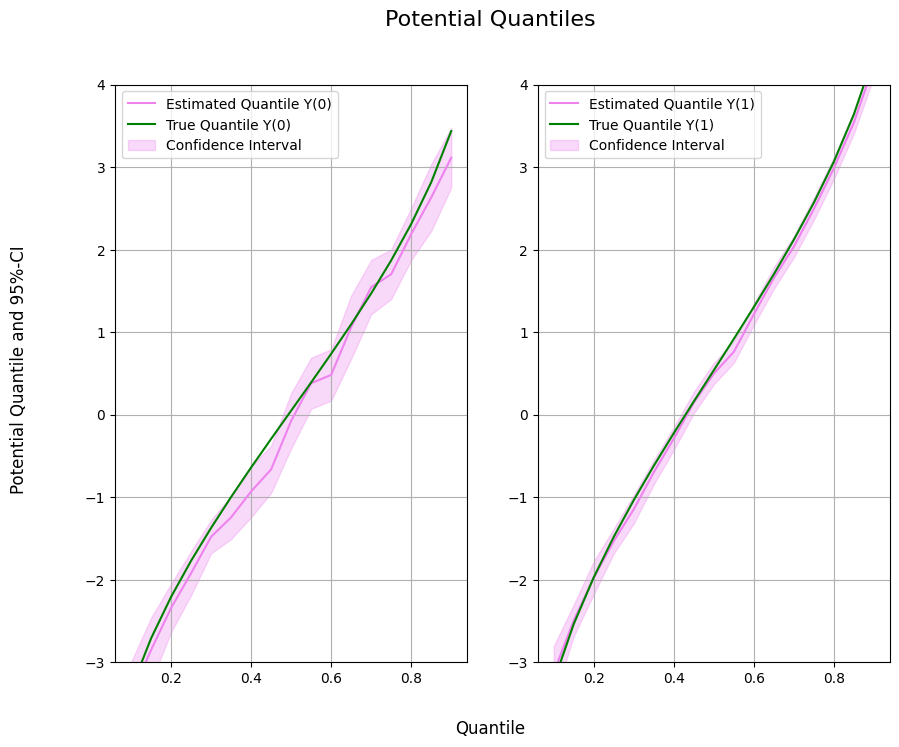
Finally, let us take a look at the estimated quantiles.
[6]:
data = {"Quantile": tau_vec, "Y(0)": Y0_quant, "Y(1)": Y1_quant,
"DML Y(0)": PQ_0, "DML Y(1)": PQ_1,
"DML Y(0) lower": ci_PQ_0[:, 0], "DML Y(0) upper": ci_PQ_0[:, 1],
"DML Y(1) lower": ci_PQ_1[:, 0], "DML Y(1) upper": ci_PQ_1[:, 1]}
df = pd.DataFrame(data)
print(df)
Quantile Y(0) Y(1) DML Y(0) DML Y(1) DML Y(0) lower \
0 0.10 -3.330658 -3.238012 -3.408565 -3.128312 -3.813293
1 0.15 -2.714279 -2.540101 -2.855780 -2.495752 -3.245512
2 0.20 -2.211403 -1.974992 -2.345903 -1.978977 -2.638264
3 0.25 -1.772612 -1.483531 -1.924002 -1.533900 -2.189737
4 0.30 -1.374335 -1.037837 -1.482483 -1.148161 -1.683942
5 0.35 -1.000320 -0.621953 -1.246879 -0.700102 -1.509196
6 0.40 -0.643623 -0.225635 -0.932973 -0.291406 -1.244455
7 0.45 -0.296759 0.159466 -0.665264 0.145245 -0.949456
8 0.50 0.046088 0.538498 -0.077319 0.496551 -0.411582
9 0.55 0.388989 0.917714 0.378834 0.760104 0.070020
10 0.60 0.735694 1.302294 0.479928 1.216344 0.168614
11 0.65 1.092453 1.700072 1.059384 1.655284 0.677614
12 0.70 1.465981 2.117900 1.544097 2.036147 1.215342
13 0.75 1.866105 2.566701 1.700015 2.493219 1.400823
14 0.80 2.306288 3.063978 2.187690 2.988463 1.872768
15 0.85 2.811282 3.638179 2.631333 3.542647 2.226524
16 0.90 3.433620 4.350533 3.113207 4.243246 2.753523
DML Y(0) upper DML Y(1) lower DML Y(1) upper
0 -3.003836 -3.448745 -2.807879
1 -2.466047 -2.687345 -2.304159
2 -2.053541 -2.177496 -1.780458
3 -1.658267 -1.684502 -1.383297
4 -1.281024 -1.319759 -0.976562
5 -0.984562 -0.844707 -0.555498
6 -0.621490 -0.428255 -0.154557
7 -0.381072 0.015698 0.274793
8 0.256944 0.367625 0.625477
9 0.687647 0.627560 0.892648
10 0.791241 1.088048 1.344640
11 1.441153 1.524657 1.785911
12 1.872852 1.907115 2.165178
13 1.999207 2.360004 2.626433
14 2.502612 2.857161 3.119766
15 3.036143 3.408539 3.676756
16 3.472891 4.098712 4.387780
[7]:
from matplotlib import pyplot as plt
plt.rcParams['figure.figsize'] = 10., 7.5
fig, (ax1, ax2) = plt.subplots(1 ,2)
ax1.grid(); ax2.grid()
ax1.plot(df['Quantile'],df['DML Y(0)'], color='violet', label='Estimated Quantile Y(0)')
ax1.plot(df['Quantile'],df['Y(0)'], color='green', label='True Quantile Y(0)')
ax1.fill_between(df['Quantile'], df['DML Y(0) lower'], df['DML Y(0) upper'], color='violet', alpha=.3, label='Confidence Interval')
ax1.legend()
ax1.set_ylim(-3, 4)
ax2.plot(df['Quantile'],df['DML Y(1)'], color='violet', label='Estimated Quantile Y(1)')
ax2.plot(df['Quantile'],df['Y(1)'], color='green', label='True Quantile Y(1)')
ax2.fill_between(df['Quantile'], df['DML Y(1) lower'], df['DML Y(1) upper'], color='violet', alpha=.3, label='Confidence Interval')
ax2.legend()
ax2.set_ylim(-3, 4)
fig.suptitle('Potential Quantiles', fontsize=16)
fig.supxlabel('Quantile')
_ = fig.supylabel('Potential Quantile and 95%-CI')
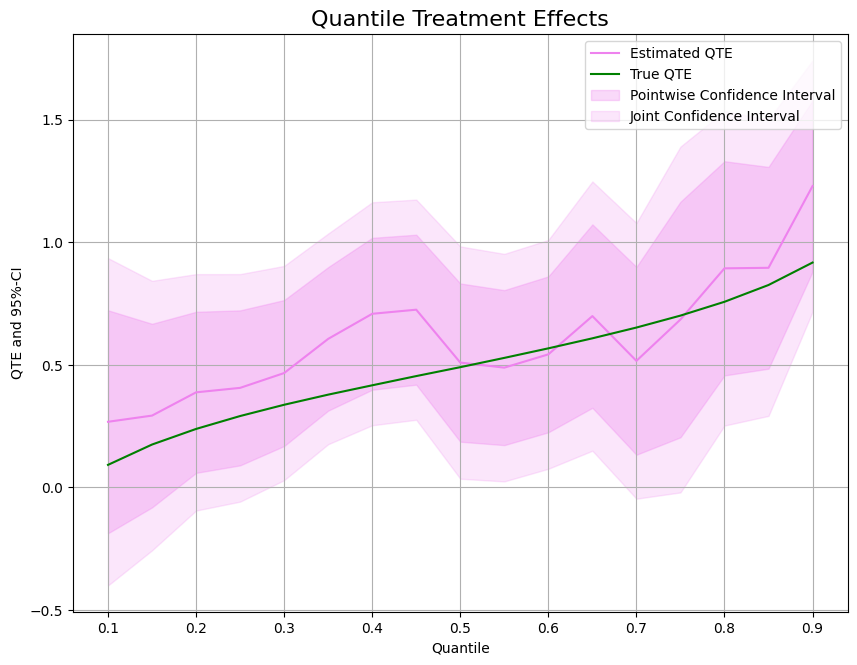
Quantile Treatment Effects (QTEs)#
In most cases, we want to evaluate the quantile treatment effect as the difference between potential quantiles. Here, different quantiles can be estimated in parallel with n_jobs_models.
To estimate the quantile treatment effect, we can use
[8]:
n_cores = multiprocessing.cpu_count()
cores_used = np.min([5, n_cores - 1])
print(f"Number of Cores used: {cores_used}")
dml_QTE = dml.DoubleMLQTE(obj_dml_data,
ml_g,
ml_m,
quantiles=tau_vec,
n_folds=5)
dml_QTE.fit(n_jobs_models=cores_used)
print(dml_QTE)
Number of Cores used: 5
================== DoubleMLQTE Object ==================
------------------ Fit summary ------------------
coef std err t P>|t| 2.5 % 97.5 %
0.10 0.267950 0.231986 1.155025 2.480800e-01 -0.186735 0.722634
0.15 0.293218 0.190982 1.535318 1.247057e-01 -0.081100 0.667536
0.20 0.388071 0.167547 2.316193 2.054771e-02 0.059685 0.716456
0.25 0.406285 0.161243 2.519710 1.174516e-02 0.090255 0.722316
0.30 0.466756 0.151819 3.074426 2.109079e-03 0.169196 0.764315
0.35 0.606129 0.149285 4.060201 4.903056e-05 0.313535 0.898722
0.40 0.708459 0.158007 4.483711 7.335609e-06 0.398770 1.018148
0.45 0.725166 0.156021 4.647873 3.353748e-06 0.419371 1.030962
0.50 0.509461 0.164608 3.094999 1.968134e-03 0.186836 0.832086
0.55 0.488811 0.161236 3.031639 2.432300e-03 0.172793 0.804828
0.60 0.542989 0.162153 3.348617 8.121584e-04 0.225175 0.860804
0.65 0.699035 0.190809 3.663529 2.487641e-04 0.325056 1.073013
0.70 0.516528 0.195377 2.643752 8.199281e-03 0.133596 0.899460
0.75 0.685107 0.245062 2.795647 5.179588e-03 0.204794 1.165419
0.80 0.893851 0.222843 4.011131 6.042844e-05 0.457088 1.330615
0.85 0.896023 0.209894 4.268942 1.964025e-05 0.484640 1.307407
0.90 1.229443 0.177995 6.907176 4.944045e-12 0.880579 1.578307
As for other dml objects, we can use bootstrap() and confint() methods to generate jointly valid confidence intervals.
[9]:
ci_QTE = dml_QTE.confint(level=0.95, joint=False)
dml_QTE.bootstrap(n_rep_boot=2000)
ci_joint_QTE = dml_QTE.confint(level=0.95, joint=True)
print(ci_joint_QTE)
2.5 % 97.5 %
0.10 -0.399692 0.935591
0.15 -0.256416 0.842853
0.20 -0.094118 0.870260
0.25 -0.057762 0.870332
0.30 0.029831 0.903681
0.35 0.176495 1.035762
0.40 0.253724 1.163194
0.45 0.276148 1.174185
0.50 0.035730 0.983192
0.55 0.024782 0.952839
0.60 0.076322 1.009656
0.65 0.149898 1.248171
0.70 -0.045754 1.078810
0.75 -0.020166 1.390379
0.80 0.252524 1.535179
0.85 0.291963 1.500084
0.90 0.717185 1.741702
As before, let us take a look at the estimated effects and confidence intervals.
[10]:
QTE = Y1_quant - Y0_quant
data = {"Quantile": tau_vec, "QTE": QTE, "DML QTE": dml_QTE.coef,
"DML QTE pointwise lower": ci_QTE['2.5 %'], "DML QTE pointwise upper": ci_QTE['97.5 %'],
"DML QTE joint lower": ci_joint_QTE['2.5 %'], "DML QTE joint upper": ci_joint_QTE['97.5 %']}
df = pd.DataFrame(data)
print(df)
Quantile QTE DML QTE DML QTE pointwise lower \
0.10 0.10 0.092646 0.267950 -0.186735
0.15 0.15 0.174177 0.293218 -0.081100
0.20 0.20 0.236411 0.388071 0.059685
0.25 0.25 0.289081 0.406285 0.090255
0.30 0.30 0.336498 0.466756 0.169196
0.35 0.35 0.378367 0.606129 0.313535
0.40 0.40 0.417988 0.708459 0.398770
0.45 0.45 0.456225 0.725166 0.419371
0.50 0.50 0.492410 0.509461 0.186836
0.55 0.55 0.528725 0.488811 0.172793
0.60 0.60 0.566600 0.542989 0.225175
0.65 0.65 0.607618 0.699035 0.325056
0.70 0.70 0.651919 0.516528 0.133596
0.75 0.75 0.700596 0.685107 0.204794
0.80 0.80 0.757690 0.893851 0.457088
0.85 0.85 0.826897 0.896023 0.484640
0.90 0.90 0.916913 1.229443 0.880579
DML QTE pointwise upper DML QTE joint lower DML QTE joint upper
0.10 0.722634 -0.399692 0.935591
0.15 0.667536 -0.256416 0.842853
0.20 0.716456 -0.094118 0.870260
0.25 0.722316 -0.057762 0.870332
0.30 0.764315 0.029831 0.903681
0.35 0.898722 0.176495 1.035762
0.40 1.018148 0.253724 1.163194
0.45 1.030962 0.276148 1.174185
0.50 0.832086 0.035730 0.983192
0.55 0.804828 0.024782 0.952839
0.60 0.860804 0.076322 1.009656
0.65 1.073013 0.149898 1.248171
0.70 0.899460 -0.045754 1.078810
0.75 1.165419 -0.020166 1.390379
0.80 1.330615 0.252524 1.535179
0.85 1.307407 0.291963 1.500084
0.90 1.578307 0.717185 1.741702
[11]:
plt.rcParams['figure.figsize'] = 10., 7.5
fig, ax = plt.subplots()
ax.grid()
ax.plot(df['Quantile'],df['DML QTE'], color='violet', label='Estimated QTE')
ax.plot(df['Quantile'],df['QTE'], color='green', label='True QTE')
ax.fill_between(df['Quantile'], df['DML QTE pointwise lower'], df['DML QTE pointwise upper'], color='violet', alpha=.3, label='Pointwise Confidence Interval')
ax.fill_between(df['Quantile'], df['DML QTE joint lower'], df['DML QTE joint upper'], color='violet', alpha=.2, label='Joint Confidence Interval')
plt.legend()
plt.title('Quantile Treatment Effects', fontsize=16)
plt.xlabel('Quantile')
_ = plt.ylabel('QTE and 95%-CI')
Local Potential Quantiles (LPQs)#
Next, we will consider local potential quantiles and the corresponding local quantile treatment effects.
Data#
We add a counfounder and an instrument to our data generating process.
[12]:
import numpy as np
import pandas as pd
import doubleml as dml
import multiprocessing
from lightgbm import LGBMClassifier
The data is generated as a location-scale model with confounding of the treatment \(D_i\) and instrument \(Z_i\)
where \(X_i\sim\mathcal{U}[-1,1]^{p}\), \(X^{(conf)}_i \sim\mathcal{U}[-1,1]\), \(Z_i\sim \mathcal{B}(1,1/2)\), \(\varepsilon_i \sim \mathcal{N}(0,1)\) and \(\eta_i \sim \mathcal{N}(0,1)\). Further, the location and scale are determined according to the following functions
[13]:
def f_loc(D, X, X_conf):
loc = 0.5*D + 2*D*X[:,4] + 2.0*(X[:,1] > 0.1) - 1.7*(X[:,0] * X[:,2] > 0) - 3*X[:,3] - 2*X_conf[:, 0]
return loc
def f_scale(D, X, X_conf):
scale = np.sqrt(0.5*D + 3*D*X[:, 0] + 0.4*X_conf[:, 0] + 2)
return scale
def generate_treatment(Z, X, X_conf):
eta = np.random.normal(size=len(Z))
d = ((0.5*Z -0.3*X[:, 0] + 0.7*X_conf[:, 0] + eta) > 0)*1.0
return d
def dgp(n=200, p=5):
X = np.random.uniform(0, 1, size=[n,p])
X_conf = np.random.uniform(-1, 1, size=[n,1])
Z = np.random.binomial(1, p=0.5, size=n)
D = generate_treatment(Z, X, X_conf)
epsilon = np.random.normal(size=n)
Y = f_loc(D, X, X_conf) + f_scale(D, X, X_conf)*epsilon
return Y, X, D, Z
Next, we will just simulate the true quantile for a range of quantiles.
[14]:
tau_vec = np.arange(0.1,0.95,0.05)
n_true = int(10e+6)
[15]:
p=5
X_true = np.random.uniform(0, 1, size=[n_true,p])
X_conf_true = np.random.uniform(-1, 1, size=[n_true,1])
Z_true = np.random.binomial(1, p=0.5, size=n_true)
eta_true = np.random.normal(size=n_true)
D1_true = generate_treatment(np.ones_like(Z_true), X_true, X_conf_true)
D0_true = generate_treatment(np.zeros_like(Z_true), X_true, X_conf_true)
epsilon_true = np.random.normal(size=n_true)
compliers = (D1_true == 1) * (D0_true == 0)
print(f'Compliance probability: {str(compliers.mean())}')
n_compliers = compliers.sum()
Y1 = f_loc(np.ones(n_compliers), X_true[compliers, :], X_conf_true[compliers, :]) + f_scale(np.ones(n_compliers), X_true[compliers, :], X_conf_true[compliers, :])*epsilon_true[compliers]
Y0 = f_loc(np.zeros(n_compliers), X_true[compliers, :], X_conf_true[compliers, :]) + f_scale(np.zeros(n_compliers), X_true[compliers, :], X_conf_true[compliers, :])*epsilon_true[compliers]
Compliance probability: 0.3245837
[16]:
Y0_quant = np.quantile(Y0, q=tau_vec)
Y1_quant = np.quantile(Y1, q=tau_vec)
print(f'Local Potential Quantile Y(0): {Y0_quant}')
print(f'Local Potential Quantile Y(1): {Y1_quant}')
Local Potential Quantile Y(0): [-4.07538443 -3.53606675 -3.10878571 -2.74402577 -2.41805621 -2.11724226
-1.83287529 -1.56018481 -1.29299726 -1.02900983 -0.76228406 -0.4895498
-0.20400735 0.10089588 0.43453524 0.81827267 1.29107127]
Local Potential Quantile Y(1): [-3.19031969 -2.53273833 -2.01574297 -1.57245066 -1.17700723 -0.81190107
-0.46807543 -0.13585644 0.1881752 0.51214922 0.84030318 1.17655394
1.53094017 1.91102953 2.33175566 2.81828926 3.4284675 ]
Let us generate \(n=10000\) observations and convert them to a DoubleMLData object.
[17]:
n = 10000
np.random.seed(42)
Y, X, D, Z = dgp(n=n,p=p)
obj_dml_data = dml.DoubleMLData.from_arrays(X, Y, D, Z)
Local Potential Quantile Estimation#
Next, we can initialize our two machine learning algorithms to train the different nuisance elements. As above, we can initialize the DoubleMLLPQ objects and call fit() to estimate the relevant parameters. To obtain confidence intervals, we can use the confint() method.
[18]:
ml_m = LGBMClassifier(n_estimators=300, learning_rate=0.05, num_leaves=10, verbose=-1, n_jobs=1)
ml_g = LGBMClassifier(n_estimators=300, learning_rate=0.05, num_leaves=10, verbose=-1, n_jobs=1)
LPQ_0 = np.full((len(tau_vec)), np.nan)
LPQ_1 = np.full((len(tau_vec)), np.nan)
ci_LPQ_0 = np.full((len(tau_vec),2), np.nan)
ci_LPQ_1 = np.full((len(tau_vec),2), np.nan)
for idx_tau, tau in enumerate(tau_vec):
print(f'Quantile: {tau}')
dml_LPQ_0 = dml.DoubleMLLPQ(obj_dml_data,
ml_g,
ml_m,
score="LPQ",
treatment=0,
quantile=tau,
n_folds=5,
trimming_threshold=0.05)
dml_LPQ_1 = dml.DoubleMLLPQ(obj_dml_data,
ml_g,
ml_m,
score="LPQ",
treatment=1,
quantile=tau,
n_folds=5,
trimming_threshold=0.05)
dml_LPQ_0.fit()
dml_LPQ_1.fit()
LPQ_0[idx_tau] = dml_LPQ_0.coef.squeeze()
LPQ_1[idx_tau] = dml_LPQ_1.coef.squeeze()
ci_LPQ_0[idx_tau, :] = dml_LPQ_0.confint(level=0.95).to_numpy()
ci_LPQ_1[idx_tau, :] = dml_LPQ_1.confint(level=0.95).to_numpy()
Quantile: 0.1
Quantile: 0.15000000000000002
Quantile: 0.20000000000000004
Quantile: 0.25000000000000006
Quantile: 0.30000000000000004
Quantile: 0.3500000000000001
Quantile: 0.40000000000000013
Quantile: 0.45000000000000007
Quantile: 0.5000000000000001
Quantile: 0.5500000000000002
Quantile: 0.6000000000000002
Quantile: 0.6500000000000001
Quantile: 0.7000000000000002
Quantile: 0.7500000000000002
Quantile: 0.8000000000000002
Quantile: 0.8500000000000002
Quantile: 0.9000000000000002
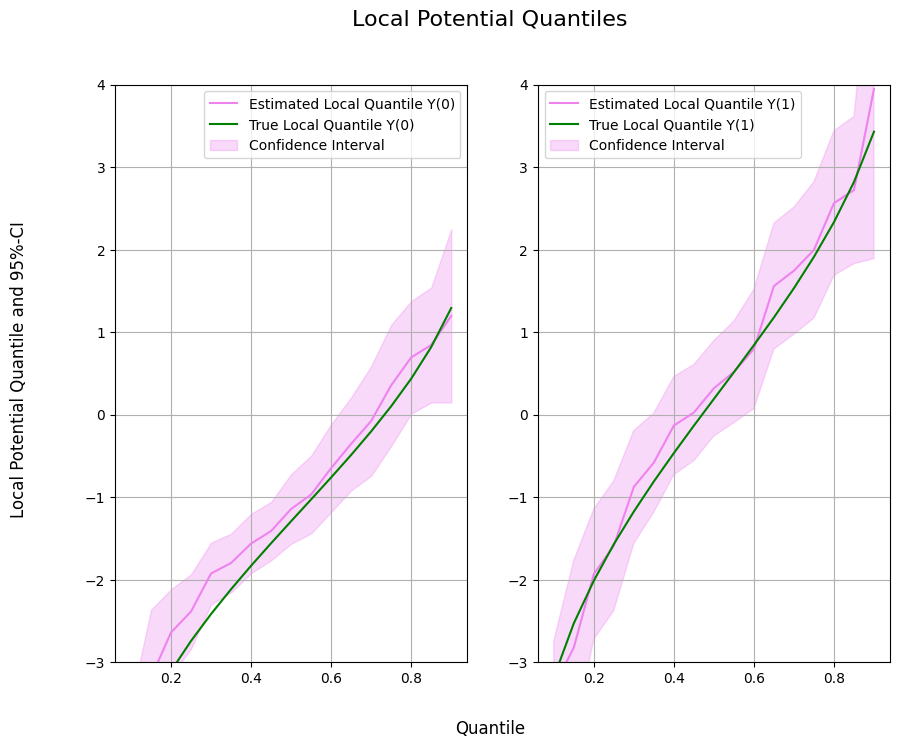
Finally, let us take a look at the estimated local quantiles.
[19]:
data = {"Quantile": tau_vec, "Y(0)": Y0_quant, "Y(1)": Y1_quant,
"DML Y(0)": LPQ_0, "DML Y(1)": LPQ_1,
"DML Y(0) lower": ci_LPQ_0[:, 0], "DML Y(0) upper": ci_LPQ_0[:, 1],
"DML Y(1) lower": ci_LPQ_1[:, 0], "DML Y(1) upper": ci_LPQ_1[:, 1]}
df = pd.DataFrame(data)
print(df)
Quantile Y(0) Y(1) DML Y(0) DML Y(1) DML Y(0) lower \
0 0.10 -4.075384 -3.190320 -4.231310 -3.306963 -4.976088
1 0.15 -3.536067 -2.532738 -3.188223 -2.826492 -4.009122
2 0.20 -3.108786 -2.015743 -2.641528 -1.935730 -3.164801
3 0.25 -2.744026 -1.572451 -2.387426 -1.590813 -2.838114
4 0.30 -2.418056 -1.177007 -1.927074 -0.878281 -2.301371
5 0.35 -2.117242 -0.811901 -1.799403 -0.583534 -2.155120
6 0.40 -1.832875 -0.468075 -1.564045 -0.134211 -1.923607
7 0.45 -1.560185 -0.135856 -1.412127 0.023256 -1.765792
8 0.50 -1.292997 0.188175 -1.144669 0.317487 -1.566024
9 0.55 -1.029010 0.512149 -0.970065 0.516255 -1.441209
10 0.60 -0.762284 0.840303 -0.649158 0.793570 -1.180951
11 0.65 -0.489550 1.176554 -0.352246 1.556792 -0.916984
12 0.70 -0.204007 1.530940 -0.077883 1.742907 -0.742128
13 0.75 0.100896 1.911030 0.354371 1.995248 -0.379614
14 0.80 0.434535 2.331756 0.692725 2.562013 0.009986
15 0.85 0.818273 2.818289 0.842746 2.720571 0.146037
16 0.90 1.291071 3.428467 1.196189 3.946433 0.145625
DML Y(0) upper DML Y(1) lower DML Y(1) upper
0 -3.486532 -3.867565 -2.746361
1 -2.367323 -3.883622 -1.769361
2 -2.118255 -2.724338 -1.147121
3 -1.936739 -2.377311 -0.804316
4 -1.552776 -1.563503 -0.193060
5 -1.443686 -1.182633 0.015565
6 -1.204482 -0.728710 0.460289
7 -1.058463 -0.559522 0.606034
8 -0.723314 -0.260360 0.895333
9 -0.498921 -0.098319 1.130829
10 -0.117366 0.070884 1.516256
11 0.212491 0.793735 2.319850
12 0.586362 0.973241 2.512572
13 1.088357 1.168931 2.821566
14 1.375465 1.685807 3.438219
15 1.539455 1.827735 3.613408
16 2.246753 1.889733 6.003134
[20]:
from matplotlib import pyplot as plt
plt.rcParams['figure.figsize'] = 10., 7.5
fig, (ax1, ax2) = plt.subplots(1 ,2)
ax1.grid(); ax2.grid()
ax1.plot(df['Quantile'],df['DML Y(0)'], color='violet', label='Estimated Local Quantile Y(0)')
ax1.plot(df['Quantile'],df['Y(0)'], color='green', label='True Local Quantile Y(0)')
ax1.fill_between(df['Quantile'], df['DML Y(0) lower'], df['DML Y(0) upper'], color='violet', alpha=.3, label='Confidence Interval')
ax1.legend()
ax1.set_ylim(-3, 4)
ax2.plot(df['Quantile'],df['DML Y(1)'], color='violet', label='Estimated Local Quantile Y(1)')
ax2.plot(df['Quantile'],df['Y(1)'], color='green', label='True Local Quantile Y(1)')
ax2.fill_between(df['Quantile'], df['DML Y(1) lower'], df['DML Y(1) upper'], color='violet', alpha=.3, label='Confidence Interval')
ax2.legend()
ax2.set_ylim(-3, 4)
fig.suptitle('Local Potential Quantiles', fontsize=16)
fig.supxlabel('Quantile')
_ = fig.supylabel('Local Potential Quantile and 95%-CI')
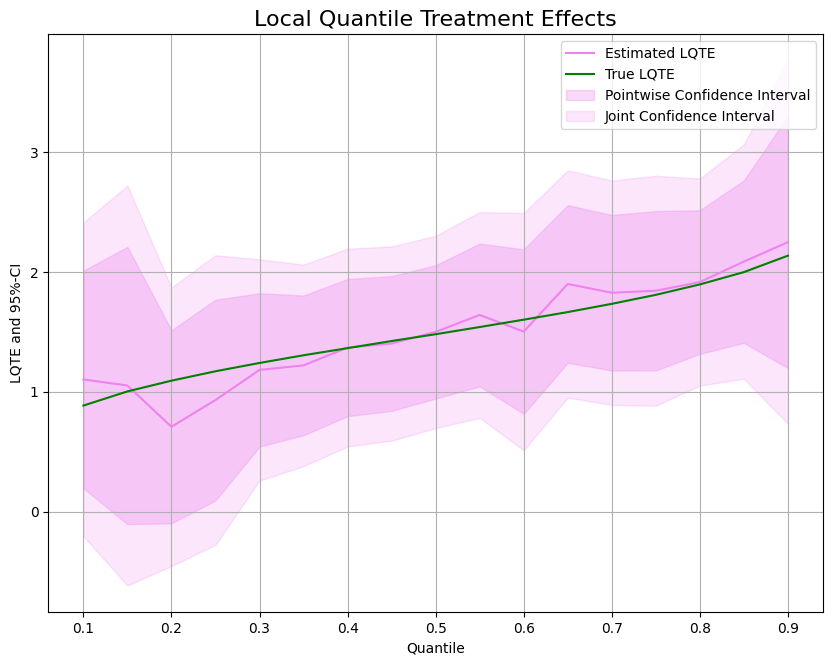
Local Quantile Treatment Effects (LQTEs)#
As for quantile treatment effects, we often want to evaluate the (local) treatment effect. To estimate local quantile treatment effects, we can use the DoubleMLQTE object and specify LPQ as the score.
As for quantile treatment effects, different quantiles can be estimated in parallel with n_jobs_models.
[21]:
n_cores = multiprocessing.cpu_count()
cores_used = np.min([5, n_cores - 1])
print(f"Number of Cores used: {cores_used}")
dml_LQTE = dml.DoubleMLQTE(obj_dml_data,
ml_g=ml_g,
ml_m=ml_m,
quantiles=tau_vec,
score='LPQ',
n_folds=5)
dml_LQTE.fit(n_jobs_models=cores_used)
print(dml_LQTE)
Number of Cores used: 5
================== DoubleMLQTE Object ==================
------------------ Fit summary ------------------
coef std err t P>|t| 2.5 % 97.5 %
0.10 1.103497 0.463325 2.381689 1.723345e-02 0.195396 2.011598
0.15 1.052502 0.590736 1.781681 7.480133e-02 -0.105318 2.210323
0.20 0.707868 0.411295 1.721071 8.523794e-02 -0.098256 1.513992
0.25 0.931479 0.427725 2.177751 2.942460e-02 0.093153 1.769805
0.30 1.182849 0.326740 3.620156 2.944253e-04 0.542451 1.823247
0.35 1.220772 0.297682 4.100923 4.115060e-05 0.637326 1.804219
0.40 1.369796 0.292105 4.689392 2.740180e-06 0.797280 1.942312
0.45 1.403425 0.287041 4.889293 1.011988e-06 0.840836 1.966015
0.50 1.501403 0.284073 5.285276 1.255151e-07 0.944630 2.058175
0.55 1.642016 0.304130 5.399056 6.699259e-08 1.045932 2.238101
0.60 1.502995 0.350518 4.287926 1.803492e-05 0.815993 2.189998
0.65 1.901148 0.335846 5.660776 1.506900e-08 1.242902 2.559394
0.70 1.827381 0.331521 5.512108 3.545605e-08 1.177611 2.477150
0.75 1.844308 0.339570 5.431306 5.594316e-08 1.178763 2.509853
0.80 1.916914 0.305775 6.269043 3.632747e-10 1.317607 2.516222
0.85 2.087947 0.346206 6.030934 1.630150e-09 1.409395 2.766499
0.90 2.278907 0.541010 4.212317 2.527644e-05 1.218546 3.339268
As for other dml objects, we can use bootstrap() and confint() methods to generate jointly valid confidence intervals.
[22]:
ci_LQTE = dml_LQTE.confint(level=0.95, joint=False)
dml_LQTE.bootstrap(n_rep_boot=2000)
ci_joint_LQTE = dml_LQTE.confint(level=0.95, joint=True)
print(ci_joint_LQTE)
2.5 % 97.5 %
0.10 -0.208300 2.415294
0.15 -0.620026 2.725031
0.20 -0.456617 1.872354
0.25 -0.279524 2.142482
0.30 0.257762 2.107935
0.35 0.377955 2.063590
0.40 0.542769 2.196824
0.45 0.590738 2.216113
0.50 0.697118 2.305687
0.55 0.780943 2.503089
0.60 0.510586 2.495405
0.65 0.950280 2.852016
0.70 0.888757 2.766005
0.75 0.882896 2.805720
0.80 1.051186 2.782643
0.85 1.107746 3.068148
0.90 0.747164 3.810650
As before, let us take a look at the estimated effects and confidence intervals.
[23]:
LQTE = Y1_quant - Y0_quant
data = {"Quantile": tau_vec, "LQTE": LQTE, "DML LQTE": dml_LQTE.coef,
"DML LQTE pointwise lower": ci_LQTE['2.5 %'], "DML LQTE pointwise upper": ci_LQTE['97.5 %'],
"DML LQTE joint lower": ci_joint_LQTE['2.5 %'], "DML LQTE joint upper": ci_joint_LQTE['97.5 %']}
df = pd.DataFrame(data)
print(df)
Quantile LQTE DML LQTE DML LQTE pointwise lower \
0.10 0.10 0.885065 1.103497 0.195396
0.15 0.15 1.003328 1.052502 -0.105318
0.20 0.20 1.093043 0.707868 -0.098256
0.25 0.25 1.171575 0.931479 0.093153
0.30 0.30 1.241049 1.182849 0.542451
0.35 0.35 1.305341 1.220772 0.637326
0.40 0.40 1.364800 1.369796 0.797280
0.45 0.45 1.424328 1.403425 0.840836
0.50 0.50 1.481172 1.501403 0.944630
0.55 0.55 1.541159 1.642016 1.045932
0.60 0.60 1.602587 1.502995 0.815993
0.65 0.65 1.666104 1.901148 1.242902
0.70 0.70 1.734948 1.827381 1.177611
0.75 0.75 1.810134 1.844308 1.178763
0.80 0.80 1.897220 1.916914 1.317607
0.85 0.85 2.000017 2.087947 1.409395
0.90 0.90 2.137396 2.278907 1.218546
DML LQTE pointwise upper DML LQTE joint lower DML LQTE joint upper
0.10 2.011598 -0.208300 2.415294
0.15 2.210323 -0.620026 2.725031
0.20 1.513992 -0.456617 1.872354
0.25 1.769805 -0.279524 2.142482
0.30 1.823247 0.257762 2.107935
0.35 1.804219 0.377955 2.063590
0.40 1.942312 0.542769 2.196824
0.45 1.966015 0.590738 2.216113
0.50 2.058175 0.697118 2.305687
0.55 2.238101 0.780943 2.503089
0.60 2.189998 0.510586 2.495405
0.65 2.559394 0.950280 2.852016
0.70 2.477150 0.888757 2.766005
0.75 2.509853 0.882896 2.805720
0.80 2.516222 1.051186 2.782643
0.85 2.766499 1.107746 3.068148
0.90 3.339268 0.747164 3.810650
[24]:
plt.rcParams['figure.figsize'] = 10., 7.5
fig, ax = plt.subplots()
ax.grid()
ax.plot(df['Quantile'],df['DML LQTE'], color='violet', label='Estimated LQTE')
ax.plot(df['Quantile'],df['LQTE'], color='green', label='True LQTE')
ax.fill_between(df['Quantile'], df['DML LQTE pointwise lower'], df['DML LQTE pointwise upper'], color='violet', alpha=.3, label='Pointwise Confidence Interval')
ax.fill_between(df['Quantile'], df['DML LQTE joint lower'], df['DML LQTE joint upper'], color='violet', alpha=.2, label='Joint Confidence Interval')
plt.legend()
plt.title('Local Quantile Treatment Effects', fontsize=16)
plt.xlabel('Quantile')
_ = plt.ylabel('LQTE and 95%-CI')