Note
-
Download Jupyter notebook:
https://docs.doubleml.org/stable/examples/py_double_ml_learner.ipynb.
Python: Choice of learners#
This notebooks contains some practical recommendations to choose the right learner and evaluate different learners for the corresponding nuisance components.
For the example, we will work with a IRM, but all of the important components are directly usable for all other models too.
To be able to compare the properties of different learners, we will start by setting the true treatment parameter to zero, fix some other parameters of the data generating process and generate several datasets to obtain some information about the distribution of the estimators.
[1]:
import numpy as np
import doubleml as dml
from doubleml.irm.datasets import make_irm_data
import warnings
warnings.filterwarnings("ignore", message="The estimated nu2 for d is not positive")
theta = 0
n_obs = 500
dim_x = 5
n_rep = 200
np.random.seed(42)
datasets = []
for i in range(n_rep):
data = make_irm_data(theta=theta, n_obs=n_obs, dim_x=dim_x,
R2_d=0.8, R2_y=0.8, return_type='DataFrame')
datasets.append(dml.DoubleMLData(data, 'y', 'd'))
Comparing different learners#
For simplicity, we will restrict ourselves to the comparison of two different types and evaluate a learner of linear type and a tree based estimator for each nuisance component (with default hyperparameters).
[2]:
from sklearn.linear_model import LinearRegression, LogisticRegressionCV
from sklearn.ensemble import GradientBoostingRegressor, GradientBoostingClassifier
from sklearn.base import clone
reg_learner_1 = LinearRegression()
reg_learner_2 = GradientBoostingRegressor()
class_learner_1 = LogisticRegressionCV()
class_learner_2 = GradientBoostingClassifier()
learner_list = [{'ml_g': reg_learner_1, 'ml_m': class_learner_1},
{'ml_g': reg_learner_2, 'ml_m': class_learner_1},
{'ml_g': reg_learner_1, 'ml_m': class_learner_2},
{'ml_g': reg_learner_2, 'ml_m': class_learner_2}]
In all combinations, we now can try to evaluate four different IRM models. To make the comparison fair, we will apply all different models to the same cross-fitting samples (usually this should not matter, we only consider this here to get slightly cleaner comparison).
Standard approach#
At first, we will look at the most straightforward approach using the inbuild nuisance losses. The nuisance_loss attribute contains the out-of-sample RMSE or Log Loss for the nuisance functions. We will save all RMSEs and the corresponding treatment estimates for all combinations of learners over all repetitions.
[3]:
from doubleml.utils import DoubleMLResampling
coefs = np.full(shape=(n_rep, len(learner_list)), fill_value=np.nan)
loss_ml_m = np.full(shape=(n_rep, len(learner_list)), fill_value=np.nan)
loss_ml_g0 = np.full(shape=(n_rep, len(learner_list)), fill_value=np.nan)
loss_ml_g1 = np.full(shape=(n_rep, len(learner_list)), fill_value=np.nan)
coverage = np.full(shape=(n_rep, len(learner_list)), fill_value=np.nan)
for i_rep in range(n_rep):
print(f"\rProcessing: {round((i_rep+1)/n_rep*100, 3)} %", end="")
dml_data = datasets[i_rep]
# define the sample splitting
smpls = DoubleMLResampling(n_folds=5, n_rep=1, n_obs=n_obs, stratify=dml_data.d).split_samples()
for i_learners, learners in enumerate(learner_list):
np.random.seed(42)
dml_irm = dml.DoubleMLIRM(dml_data,
ml_g=clone(learners['ml_g']),
ml_m=clone(learners['ml_m']),
draw_sample_splitting=False)
dml_irm.set_sample_splitting(smpls)
dml_irm.fit(n_jobs_cv=5)
coefs[i_rep, i_learners] = dml_irm.coef[0]
loss_ml_m[i_rep, i_learners] = dml_irm.nuisance_loss['ml_m'][0][0]
loss_ml_g0[i_rep, i_learners] = dml_irm.nuisance_loss['ml_g0'][0][0]
loss_ml_g1[i_rep, i_learners] = dml_irm.nuisance_loss['ml_g1'][0][0]
confint = dml_irm.confint()
coverage[i_rep, i_learners] = (confint['2.5 %'].iloc[0] <= theta) & (confint['97.5 %'].iloc[0] >= theta)
print(f'\nCoverage: {coverage.mean(0)}')
Processing: 100.0 %
Coverage: [0.935 0.65 0.975 0.94 ]
Next, let us take a look at the corresponding results
[4]:
import pandas as pd
colnames = ['Linear + Logit','Boost + Logit', 'Linear + Boost', 'Boost + Boost']
df_coefs = pd.DataFrame(coefs, columns=colnames)
df_ml_m = pd.DataFrame(loss_ml_m, columns=colnames)
df_ml_g0 = pd.DataFrame(loss_ml_g0, columns=colnames)
df_ml_g1 = pd.DataFrame(loss_ml_g1, columns=colnames)
[5]:
import seaborn as sns
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 2, figsize=(15, 5))
fig.suptitle('Learner Comparison')
sns.kdeplot(data=df_coefs,ax=axes[0][0], fill=True, alpha=0.3)
sns.kdeplot(data=df_ml_m, ax=axes[0][1], fill=True, alpha=0.3, legend=False)
sns.kdeplot(data=df_ml_g0, ax=axes[1][0], fill=True, alpha=0.3, legend=False)
sns.kdeplot(data=df_ml_g1, ax=axes[1][1], fill=True, alpha=0.3)
axes[0][0].title.set_text('Estimated Parameter')
axes[0][1].title.set_text('Log Loss ml_m')
axes[1][0].title.set_text('RMSE ml_g0')
axes[1][1].title.set_text('RMSE ml_g1')
plt.subplots_adjust(left=0.1,
bottom=0.1,
right=0.9,
top=0.9,
wspace=0.4,
hspace=0.4)
plt.show()
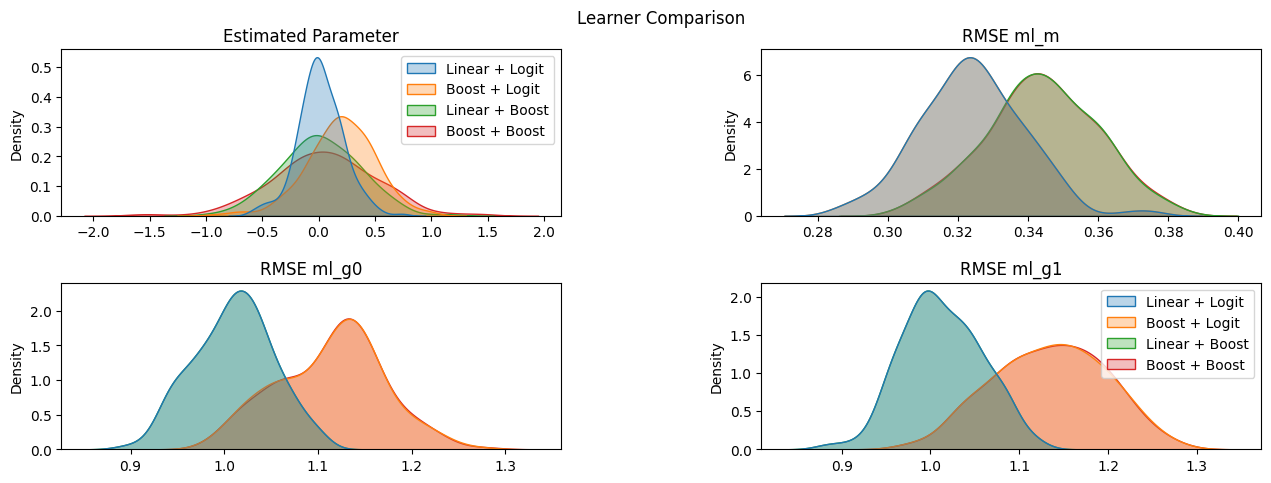
We can now easily observe that in this setting, the linear learners are able to approximate the corresponding nuisance functions better than the boosting algorithm (as should be expected since the data is generated accordingly).
Let us take a look at what would have happend if a each repetition for each nuisance element, we would have selected the learner with smallest out-of-sample loss (in our example this corresponds to minimizing the product of losses). Remark that we cannot select different learners for ml_g0 and ml_g1.
[6]:
selected_learners = (loss_ml_m * (loss_ml_g0 + loss_ml_g1)).argmin(axis=1)
np.unique(selected_learners, return_counts=True)
[6]:
(array([0, 2]), array([194, 6]))
Most of the time, we will use linear learners for both nuisance elements. Sometimes the tree-based estimator is chosen for the propensity score ml_m. Let us compare which learners, how the estimated coefficients would have performed with the selected learners.
[7]:
print(f'Coverage of selected learners: {np.mean(np.array([coverage[i_rep, selected_learners[i_rep]] for i_rep in range(n_rep)]))}')
selected_coefs = np.array([coefs[i_rep, selected_learners[i_rep]] for i_rep in range(n_rep)])
df_coefs['Selected'] = selected_coefs
sns.kdeplot(data=df_coefs, fill=True, alpha=0.3)
plt.show()
Coverage of selected learners: 0.94
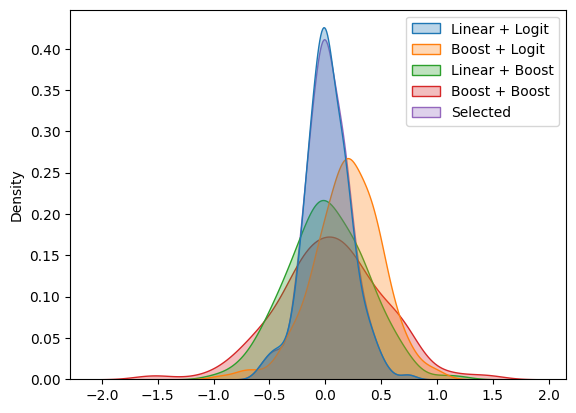
This procedure will be generally valid as long as we do not compare a excessively large number of different learners.
Custom evaluation metrics#
If one wants to evaluate a learner based on some other metric/loss it is possible to use the inbuilt evaluate_learners() method. Without further arguments this will default to the RMSE for all nuisance components and result in the same output as the nuisance_loss attribute for regressors.
[8]:
print(dml_irm.evaluate_learners())
print(dml_irm.nuisance_loss)
{'ml_g0': array([[1.02699695]]), 'ml_g1': array([[1.06270135]]), 'ml_m': array([[0.34980811]])}
{'ml_g0': array([[1.02699695]]), 'ml_g1': array([[1.06270135]]), 'ml_m': array([[0.39186467]])}
To evaluate a self-defined metric, the user has to hand over a callable. In this example, we define the mean absolute deviation as an error metric.
Remark that the metric should be able to handle nan values, since e.g. in the IRM model the learner ml_g is used to onto two different subsamples. As a result, we have two different nuisance components for
which are both fitted with the learner ml_g. Of course, we can only observe the target value for \(g_0(x)\) if \(D=0\) and vice versa, resulting in nan values for all other observations.
[9]:
from sklearn.metrics import mean_absolute_error
def mae(y_true, y_pred):
subset = np.logical_not(np.isnan(y_true))
return mean_absolute_error(y_true[subset], y_pred[subset])
dml_irm.evaluate_learners(metric=mae)
[9]:
{'ml_g0': array([[0.82329138]]),
'ml_g1': array([[0.85402594]]),
'ml_m': array([[0.20167273]])}
Another option is to access the out-of-sample predictions and target values for the nuisance elements via the nuisance_targets and predictions attributes.
[10]:
print(dml_irm.nuisance_targets['ml_g1'].shape)
print(dml_irm.predictions['ml_g1'].shape)
(500, 1, 1)
(500, 1, 1)
For most models minimizing the RMSE for each learner should result in improved performance as the theoretical backbone of the DML Framework is build on \(\ell_2\)-convergence rates for the nuisance estimates (Chernozhukov et al. (2018)). But for some models (e.g. classification learners) it might be helpful to further check other error metrics (e.g. as in scikit-learn) to gain a overview whether the nuisance function can be approximated sufficiently well. Specifically, for binary classifications the log loss is a common and stable choice as it is also a calibrated metric.
Of course, if one has some prior knowledge on functional form assumptions (e.g. linearity as in the IRM example above) using these learners will usually improve the performance of the estimator and might speed up computation time.
Computation time#
The choice of the learner has a huge impact on the computation time of the DoubleML models. As the largest part of the computation time is usually used to train the learners for the nuisance components, some clever choices of learners and hyperparameters can speed up the computation time.
Resourcewise, most implementations support the n_jobs_cv argument, which can parallelize the k-fold estimation and might speed up the calculation nearly up to \(k\)-times if the resources are available.
[11]:
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from time import perf_counter
np.random.seed(42)
n_obs = 1000
dml_data = dml.DoubleMLData(make_irm_data(theta=0, n_obs=n_obs, dim_x=20, return_type='DataFrame'), 'y', 'd')
# define the sample splitting
smpls = DoubleMLResampling(n_folds=5, n_rep=1, n_obs=n_obs, stratify=dml_data.d).split_samples()
dml_irm = dml.DoubleMLIRM(dml_data,
ml_g=RandomForestRegressor(),
ml_m=RandomForestClassifier(),
draw_sample_splitting=False)
dml_irm.set_sample_splitting(smpls)
np.random.seed(42)
t_1_start = perf_counter()
dml_irm.fit()
t_1_stop = perf_counter()
print(f'Time without parallelization of crossfitting: {round(t_1_stop - t_1_start, 4)} seconds')
np.random.seed(42)
t_2_start = perf_counter()
dml_irm.fit(n_jobs_cv=5)
t_2_stop = perf_counter()
print(f'Time with parallelization of crossfitting: {round(t_2_stop - t_2_start, 4)} seconds')
print(f'Speedup of factor {round((t_1_stop - t_1_start) / (t_2_stop - t_2_start), 2)}')
Time without parallelization of crossfitting: 4.3593 seconds
Time with parallelization of crossfitting: 0.8996 seconds
Speedup of factor 4.85
Other more helpful ways to improve computation time will largly depend on the implemented learner. Of course linear learners are quite fast, but if no functional form restrictions are known Boosting or Random Forest might be better default options to saveguard against wrong model assumptions. Especially Boosting performs very well as a default option for tabular data. As a general recommendation all popular Boosting frameworks (XGBoost, Lightgbm, Catboost, etc.) should improve computation time. But this might vary heavily with the number of features in your dataset. Let us compare the computation time with Boosting and Random Forest (we increase the sample size and the number of features).
[12]:
from xgboost import XGBClassifier, XGBRegressor
from lightgbm import LGBMClassifier, LGBMRegressor
np.random.seed(42)
n_obs = 1000
dml_data = dml.DoubleMLData(make_irm_data(theta=0, n_obs=n_obs, dim_x=50, return_type='DataFrame'), 'y', 'd')
# define the sample splitting
smpls = DoubleMLResampling(n_folds=5, n_rep=1, n_obs=n_obs, stratify=dml_data.d).split_samples()
np.random.seed(42)
t_1_start = perf_counter()
dml_irm = dml.DoubleMLIRM(dml_data,
ml_g=RandomForestRegressor(),
ml_m=RandomForestClassifier(),
draw_sample_splitting=False)
dml_irm.set_sample_splitting(smpls)
dml_irm.fit()
t_1_stop = perf_counter()
print(f'Time without RandomForest (Scikit-Learn): {round(t_1_stop - t_1_start, 4)} seconds')
np.random.seed(42)
t_2_start = perf_counter()
dml_irm = dml.DoubleMLIRM(dml_data,
ml_g=XGBRegressor(),
ml_m=XGBClassifier(),
draw_sample_splitting=False)
dml_irm.set_sample_splitting(smpls)
dml_irm.fit()
t_2_stop = perf_counter()
print(f'Time with XGBoost: {round(t_2_stop - t_2_start, 4)} seconds')
print(f'Speedup of factor {round((t_1_stop - t_1_start) / (t_2_stop - t_2_start), 2)}')
np.random.seed(42)
t_3_start = perf_counter()
dml_irm = dml.DoubleMLIRM(dml_data,
ml_g=LGBMRegressor(verbose=-1),
ml_m=LGBMClassifier(verbose=-1),
draw_sample_splitting=False)
dml_irm.set_sample_splitting(smpls)
dml_irm.fit()
t_3_stop = perf_counter()
print(f'Time with LightGBM: {round(t_3_stop - t_3_start, 4)} seconds')
print(f'Speedup of factor {round((t_1_stop - t_1_start) / (t_3_stop - t_3_start), 2)}')
Time without RandomForest (Scikit-Learn): 8.8445 seconds
Time with XGBoost: 1.8681 seconds
Speedup of factor 4.73
Time with LightGBM: 0.4814 seconds
Speedup of factor 18.37
References#
Bach, P., Schacht, O., Chernozhukov, V., Klaassen, S., & Spindler, M. (2024, March). Hyperparameter Tuning for Causal Inference with Double Machine Learning: A Simulation Study. In Causal Learning and Reasoning (pp. 1065-1117). PMLR.