import pandas as pd
# TODO: Fix Data loading (from URL?)
lalonde_exp = pd.read_csv('../../datasets/imbens-cleaned/imbens1.csv')
lalonde_exp.shape(445, 11)Tools for Causality
Grenoble, Sept 25 - 29, 2023
Philipp Bach, Sven Klaassen
We illustrate the use of sensitivity analysis on the famous Lalonde data set. There are basically two different samples, one experimental and one non-experimental subset. […]. The samples have been used for sensitivity analysis in Imbens (2003) and, more recently, in Veitch and Zaveri (2020).
A nice feature about the Lalonde data set is that makes it possible to compare the results from an experimental setting to an observational setting. Hence, we can compare the robustness of the results from an observational causal study to an experimental study, which is very unlikely affected by unobserved confounding.
In this notebook, we replicate the sensitivity analysis in Imbens (2003) and Veitch and Zaveri (2020). There a confounding scenario is considered that would introduce a bias of $1000.1
We organize our analysis along the lines of Imbens (2003) and Veitch and Zaveri (2020) who consider two different sample specifications:
The original data files are available from Veitch and Zaveri (2020).
The data contains nine covariates
and the outcome (earnings in 1978). The treatment variable is an indicator for participation in the job training program.
import pandas as pd
# TODO: Fix Data loading (from URL?)
lalonde_exp = pd.read_csv('../../datasets/imbens-cleaned/imbens1.csv')
lalonde_exp.shape(445, 11)# TODO: Fix Data loading (from URL?)
lalonde_restricted = pd.read_csv('../../datasets/imbens-cleaned/imbens4.csv')
lalonde_restricted.shape(390, 11)We mainly consider past earnings as a benchmark variable. To see the difference across the experimental and non-experimental samples, we plot the distribution of past earnings for the treated and control units.
# Experimental sample
lalonde_exp.groupby('treatment')['RE75'].plot.hist(bins = 20, alpha = 0.8, density = True, legend = True)treatment
0.0 Axes(0.125,0.11;0.775x0.77)
1.0 Axes(0.125,0.11;0.775x0.77)
Name: RE75, dtype: object
# Experimental sample
lalonde_restricted.groupby('treatment')['RE75'].plot.hist(bins = 20, alpha = 0.8, density = True, legend = True)treatment
0.0 Axes(0.125,0.11;0.775x0.77)
1.0 Axes(0.125,0.11;0.775x0.77)
Name: RE75, dtype: object
We will first estimate the Average Treatment Effect (ATE) of the training on earnings using a partially linear regression model.
import doubleml as dmlx_cols = lalonde_exp.columns.drop(['RE78', 'treatment']).to_list()
dml_data_exp = dml.DoubleMLData(lalonde_exp, y_col='RE78',
d_cols='treatment',
x_cols=x_cols)dml_data_restricted = dml.DoubleMLData(lalonde_restricted, y_col='RE78',
d_cols='treatment',
x_cols=x_cols)We use the same specification for the learners as in Veitch and Zaveri (2020).
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
N_EST = 100
MAX_DEPTH = 5
ml_m = RandomForestClassifier(
random_state=42, n_estimators=N_EST, max_depth=MAX_DEPTH)
ml_g = RandomForestRegressor(
random_state=42, n_estimators=N_EST, max_depth=MAX_DEPTH)import numpy as np
np.random.seed(123)
dml_plr_exp = dml.DoubleMLPLR(dml_data_exp, ml_g, ml_m, n_folds = 10)
dml_plr_exp.fit()<doubleml.double_ml_plr.DoubleMLPLR at 0x21ccb347fd0>np.random.seed(123)
dml_plr_restricted = dml.DoubleMLPLR(dml_data_restricted, ml_g, ml_m, n_folds = 10)
dml_plr_restricted.fit()<doubleml.double_ml_plr.DoubleMLPLR at 0x21ccb53d4d0>Let us summarize the input in a table.
results_plr_df = pd.concat([dml_plr_exp.summary, dml_plr_restricted.summary], keys = ["Experimental", "Restricted"])
results_plr_df.round(3)| coef | std err | t | P>|t| | 2.5 % | 97.5 % | ||
|---|---|---|---|---|---|---|---|
| Experimental | treatment | 1726.899 | 677.070 | 2.551 | 0.011 | 399.867 | 3053.932 |
| Restricted | treatment | 2283.652 | 1029.706 | 2.218 | 0.027 | 265.466 | 4301.838 |
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
colors = sns.color_palette()
plt.rcParams['figure.figsize'] = 10., 7.5
sns.set(font_scale=1.5)
sns.set_style('whitegrid', {'axes.spines.top': False,
'axes.spines.bottom': False,
'axes.spines.left': False,
'axes.spines.right': False})
plt.figure(figsize=(10, 15))
errors = np.full((2, results_plr_df.shape[0]), np.nan)
errors[0, :] = results_plr_df['coef'] - results_plr_df['2.5 %']
errors[1, :] = results_plr_df['97.5 %'] - results_plr_df['coef']
plt.errorbar(['Experimental', 'Restricted'], results_plr_df.coef, fmt='o', yerr=errors)
plt.title('Lalonde Data: PLR Estimates')
plt.ylabel('Coefficients and 95%-CI')
_ = plt.xlabel('Data Set')
Now let’s perform some sensitivity analysis for the different samples. We start with the experimental sample.
General setting: No particular \(H_0\) provided.
dml_plr_exp.sensitivity_analysis()
print(dml_plr_exp.sensitivity_summary)================== Sensitivity Analysis ==================
------------------ Scenario ------------------
Significance Level: level=0.95
Sensitivity parameters: cf_y=0.03; cf_d=0.03, rho=1.0
------------------ Bounds with CI ------------------
CI lower theta lower theta theta upper CI upper
treatment 169.541845 1309.011131 1726.89944 2144.787748 3235.412501
------------------ Robustness Values ------------------
H_0 RV (%) RVa (%)
treatment 0.0 11.820295 4.117965dml_plr_restricted.sensitivity_analysis()
print(dml_plr_restricted.sensitivity_summary)================== Sensitivity Analysis ==================
------------------ Scenario ------------------
Significance Level: level=0.95
Sensitivity parameters: cf_y=0.03; cf_d=0.03, rho=1.0
------------------ Bounds with CI ------------------
CI lower theta lower theta theta upper CI upper
treatment -223.933549 1487.96296 2283.65209 3079.341221 4770.699752
------------------ Robustness Values ------------------
H_0 RV (%) RVa (%)
treatment 0.0 8.368444 2.189394Let us replicate the benchmark analysis from Imbens (2003) and Veitch and Zaveri (2020). In their analyses, they consider a confounding scenario that would introduce a bias of $1000. One possibility would be to consider a null hypothesis that corresponds to a value \(\hat{\theta}_0 - 1000\). However, as we are going to visualize our results in a contour plot, this enables us to consider various bias levels at once.
We consider the following benchmark scenarios
benchmark_sets_single = [[var] for var in x_cols]
benchmark_sets_earnings = [['RE75', 'pos75'],
['RE74', 'RE75', 'pos74', 'pos75']]
benchmark_scenarios_single = [var for var in x_cols]
benchmark_scenarios_earnings = ["recent earnings", 'preprogram earnings']
benchmark_sets = benchmark_sets_single + benchmark_sets_earnings
benchmark_scenarios = benchmark_scenarios_single + benchmark_scenarios_earnings
df_benchmark_exp = pd.DataFrame({'scenario': benchmark_scenarios,
'benchmarksets': benchmark_sets,
'cf_y': np.nan, 'cf_d': np.nan, 'rho': np.nan,
'delta_theta': np.nan})
df_benchmark_restricted = df_benchmark_exp.copy()This can take a while as we have to estimate a new PLR for each benchmark scenario.
# Experimental data
for this_scenario in range(len(benchmark_scenarios)):
bench_set = benchmark_sets[this_scenario]
bench_results = dml_plr_exp.sensitivity_benchmark(bench_set)
df_benchmark_exp.loc[this_scenario, 'cf_y'] = bench_results['cf_y'][0]
df_benchmark_exp.loc[this_scenario, 'cf_d'] = bench_results['cf_d'][0]
df_benchmark_exp.loc[this_scenario, 'rho'] = bench_results['rho'][0]
df_benchmark_exp.loc[this_scenario, 'delta_theta'] = bench_results['delta_theta'][0]
df_benchmark_exp.round(3)C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:5: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:5: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:5: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:5: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:5: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:5: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:5: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:5: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:5: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:5: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:5: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\2384365899.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
| scenario | benchmarksets | cf_y | cf_d | rho | delta_theta | |
|---|---|---|---|---|---|---|
| 0 | age | [age] | 0.000 | 0.000 | -1.000 | -61.852 |
| 1 | education | [education] | 0.020 | 0.014 | 0.539 | 123.734 |
| 2 | black | [black] | 0.017 | 0.000 | -1.000 | -64.900 |
| 3 | hispanic | [hispanic] | 0.000 | 0.000 | -1.000 | -14.380 |
| 4 | married | [married] | 0.000 | 0.004 | -1.000 | -112.151 |
| 5 | RE74 | [RE74] | 0.000 | 0.000 | -1.000 | -289.242 |
| 6 | RE75 | [RE75] | 0.007 | 0.016 | -1.000 | -172.036 |
| 7 | pos74 | [pos74] | 0.003 | 0.001 | -1.000 | -90.068 |
| 8 | pos75 | [pos75] | 0.003 | 0.000 | -1.000 | -106.454 |
| 9 | recent earnings | [RE75, pos75] | 0.011 | 0.015 | -0.515 | -91.123 |
| 10 | preprogram earnings | [RE74, RE75, pos74, pos75] | 0.000 | 0.036 | -1.000 | -78.475 |
# Restricted sample
# Numerical instabilities
for this_scenario in range(len(benchmark_scenarios)):
bench_set = benchmark_sets[this_scenario]
bench_results = dml_plr_restricted.sensitivity_benchmark(bench_set)
df_benchmark_restricted.loc[this_scenario, 'cf_y'] = bench_results['cf_y'][0]
df_benchmark_restricted.loc[this_scenario, 'cf_d'] = bench_results['cf_d'][0]
df_benchmark_restricted.loc[this_scenario, 'rho'] = bench_results['rho'][0]
df_benchmark_restricted.loc[this_scenario, 'delta_theta'] = bench_results['delta_theta'][0]
df_benchmark_restricted.round(3)C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:9: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:9: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:9: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:9: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:9: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:9: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:9: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:9: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:9: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:9: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\anaconda3\Lib\site-packages\doubleml\_utils_checks.py:204: UserWarning:
Propensity predictions from learner RandomForestClassifier(max_depth=5, random_state=42) for ml_m are close to zero or one (eps=1e-12).
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:6: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:7: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:8: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
C:\Users\PuD\AppData\Local\Temp\ipykernel_26336\1472702386.py:9: FutureWarning:
Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
| scenario | benchmarksets | cf_y | cf_d | rho | delta_theta | |
|---|---|---|---|---|---|---|
| 0 | age | [age] | 0.000 | 0.187 | 1.000 | 789.143 |
| 1 | education | [education] | 0.055 | 0.014 | 0.146 | 103.249 |
| 2 | black | [black] | 0.006 | 0.191 | 0.523 | 440.470 |
| 3 | hispanic | [hispanic] | 0.000 | 0.004 | -1.000 | -37.113 |
| 4 | married | [married] | 0.000 | 0.110 | 1.000 | 117.655 |
| 5 | RE74 | [RE74] | 0.000 | 0.011 | -1.000 | -37.487 |
| 6 | RE75 | [RE75] | 0.010 | 0.019 | -0.970 | -340.159 |
| 7 | pos74 | [pos74] | 0.003 | 0.030 | 0.068 | 16.033 |
| 8 | pos75 | [pos75] | 0.000 | 0.000 | -1.000 | -124.626 |
| 9 | recent earnings | [RE75, pos75] | 0.018 | 0.036 | -0.733 | -475.483 |
| 10 | preprogram earnings | [RE74, RE75, pos74, pos75] | 0.011 | 0.204 | -0.841 | -942.301 |
Let us visualize the results in a contour plot. Note that the results shown in the contour plot are conservative in the sense that the parameter \(\rho\) is set to a value of 1. Using lower values of \(\rho\) would lead to less conservative results. However it is not possible to combine multiple values of \(\rho\) in the same contour plot as it operates as a scaling factor for the bias.
benchmarks_dict = {'cf_d' : df_benchmark_exp['cf_d'].astype(float).round(3).tolist(),
'cf_y' : df_benchmark_exp['cf_y'].astype(float).round(3).tolist(),
'name' : benchmark_scenarios}
contour_exp = dml_plr_exp.sensitivity_plot(grid_bounds = (0.2, 0.2), benchmarks = benchmarks_dict)
contour_exp.show()
print(df_benchmark_exp.round(3)) scenario benchmarksets cf_y cf_d rho \
0 age [age] 0.000 0.000 -1.000
1 education [education] 0.020 0.014 0.539
2 black [black] 0.017 0.000 -1.000
3 hispanic [hispanic] 0.000 0.000 -1.000
4 married [married] 0.000 0.004 -1.000
5 RE74 [RE74] 0.000 0.000 -1.000
6 RE75 [RE75] 0.007 0.016 -1.000
7 pos74 [pos74] 0.003 0.001 -1.000
8 pos75 [pos75] 0.003 0.000 -1.000
9 recent earnings [RE75, pos75] 0.011 0.015 -0.515
10 preprogram earnings [RE74, RE75, pos74, pos75] 0.000 0.036 -1.000
delta_theta
0 -61.852
1 123.734
2 -64.900
3 -14.380
4 -112.151
5 -289.242
6 -172.036
7 -90.068
8 -106.454
9 -91.123
10 -78.475 benchmarks_dict = {'cf_d' : df_benchmark_restricted['cf_d'].astype(float).round(3).tolist(),
'cf_y' : df_benchmark_restricted['cf_y'].astype(float).round(3).tolist(),
'name' : benchmark_scenarios}
contour_restricted = dml_plr_restricted.sensitivity_plot(grid_bounds = (0.2, 0.2), benchmarks = benchmarks_dict)
contour_restricted.show()
print(df_benchmark_restricted.round(3)) scenario benchmarksets cf_y cf_d rho \
0 age [age] 0.000 0.187 1.000
1 education [education] 0.055 0.014 0.146
2 black [black] 0.006 0.191 0.523
3 hispanic [hispanic] 0.000 0.004 -1.000
4 married [married] 0.000 0.110 1.000
5 RE74 [RE74] 0.000 0.011 -1.000
6 RE75 [RE75] 0.010 0.019 -0.970
7 pos74 [pos74] 0.003 0.030 0.068
8 pos75 [pos75] 0.000 0.000 -1.000
9 recent earnings [RE75, pos75] 0.018 0.036 -0.733
10 preprogram earnings [RE74, RE75, pos74, pos75] 0.011 0.204 -0.841
delta_theta
0 789.143
1 103.249
2 440.470
3 -37.113
4 117.655
5 -37.487
6 -340.159
7 16.033
8 -124.626
9 -475.483
10 -942.301 Let us compare the robustness of the analysis to a fixed value for the bias (\(=1000\$\)) by specifying an alternative \(H_0\).
# Restricted sample (observed data)
bias_value = 1000
H0 = dml_plr_restricted.coef - bias_value
dml_plr_restricted.sensitivity_analysis(null_hypothesis = H0)
print(dml_plr_restricted.sensitivity_summary)================== Sensitivity Analysis ==================
------------------ Scenario ------------------
Significance Level: level=0.95
Sensitivity parameters: cf_y=0.03; cf_d=0.03, rho=1.0
------------------ Bounds with CI ------------------
CI lower theta lower theta theta upper CI upper
treatment -223.933549 1487.96296 2283.65209 3079.341221 4770.699752
------------------ Robustness Values ------------------
H_0 RV (%) RVa (%)
treatment 1283.65209 3.755653 0.000348benchmark_setting_restricted = {'cf_d' : [df_benchmark_restricted.iloc[10]['cf_d'].astype(float).round(3)],
'cf_y' : [df_benchmark_restricted.iloc[10]['cf_y'].astype(float).round(3)],
'name' : [benchmark_scenarios[10]]}
contour_restricted_h0 = dml_plr_restricted.sensitivity_plot(grid_bounds = (0.25, 0.25),
benchmarks = benchmark_setting_restricted)
contour_restricted_h0.show()print(df_benchmark_restricted.iloc[10])scenario preprogram earnings
benchmarksets [RE74, RE75, pos74, pos75]
cf_y 0.010842
cf_d 0.204396
rho -0.840951
delta_theta -942.301403
Name: 10, dtype: object# Experimental sample (observed data)
H0 = dml_plr_exp.coef - bias_value
dml_plr_exp.sensitivity_analysis(null_hypothesis = H0)
print(dml_plr_exp.sensitivity_summary)================== Sensitivity Analysis ==================
------------------ Scenario ------------------
Significance Level: level=0.95
Sensitivity parameters: cf_y=0.03; cf_d=0.03, rho=1.0
------------------ Bounds with CI ------------------
CI lower theta lower theta theta upper CI upper
treatment 169.541845 1309.011131 1726.89944 2144.787748 3235.412501
------------------ Robustness Values ------------------
H_0 RV (%) RVa (%)
treatment 726.89944 7.028315 0.000544benchmark_setting_exp = {'cf_d' : [df_benchmark_exp.iloc[10]['cf_d'].astype(float).round(3)],
'cf_y' : [df_benchmark_exp.iloc[10]['cf_y'].astype(float).round(3)],
'name' : [benchmark_scenarios[10]]}
contour_exp_h0 = dml_plr_exp.sensitivity_plot(grid_bounds = (0.25, 0.25),
benchmarks = benchmark_setting_exp)
contour_exp_h0.show()print(df_benchmark_exp.iloc[10])scenario preprogram earnings
benchmarksets [RE74, RE75, pos74, pos75]
cf_y 0.0
cf_d 0.035982
rho -1.0
delta_theta -78.475004
Name: 10, dtype: objectAlternatively, we can use an entirely nonparametric model to estimate the ATE or the Average Treatment Effect on the Treated (ATTE).
np.random.seed(123)
dml_irm_ate_exp = dml.DoubleMLIRM(dml_data_exp, ml_g, ml_m, n_folds = 10, score = 'ATE', trimming_threshold = 0.025)
dml_irm_ate_exp.fit()
# TODO: Diagnostics - Prop Score!
# TODO: Compare results for different learners (LightGBM, Lasso)
# TODO: Use IRM for ATTE only!<doubleml.double_ml_irm.DoubleMLIRM at 0x21ccb629050>np.random.seed(123)
dml_irm_ate_restricted = dml.DoubleMLIRM(dml_data_restricted, ml_g, ml_m, n_folds = 10, score = 'ATE', trimming_threshold = 0.025)
dml_irm_ate_restricted.fit()<doubleml.double_ml_irm.DoubleMLIRM at 0x21ccbcb57d0>results_irm_ate_df = pd.concat([dml_irm_ate_exp.summary, dml_irm_ate_restricted.summary], keys = ["Experimental", "Restricted"])
results_irm_ate_df.round(3)| coef | std err | t | P>|t| | 2.5 % | 97.5 % | ||
|---|---|---|---|---|---|---|---|
| Experimental | treatment | 1676.152 | 694.596 | 2.413 | 0.016 | 314.769 | 3037.535 |
| Restricted | treatment | 4173.361 | 669.070 | 6.238 | 0.000 | 2862.007 | 5484.715 |
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
colors = sns.color_palette()
plt.rcParams['figure.figsize'] = 10., 7.5
sns.set(font_scale=1.5)
sns.set_style('whitegrid', {'axes.spines.top': False,
'axes.spines.bottom': False,
'axes.spines.left': False,
'axes.spines.right': False})
plt.figure(figsize=(10, 15))
errors = np.full((2, results_irm_ate_df.shape[0]), np.nan)
errors[0, :] = results_irm_ate_df['coef'] - results_irm_ate_df['2.5 %']
errors[1, :] = results_irm_ate_df['97.5 %'] - results_irm_ate_df['coef']
plt.errorbar(['Experimental', 'Restricted'], results_irm_ate_df.coef, fmt='o', yerr=errors)
plt.title('Lalonde Data: IRM Estimates (ATE)')
plt.ylabel('Coefficients and 95%-CI')
_ = plt.xlabel('Data Set')
np.random.seed(123)
dml_irm_atte_exp = dml.DoubleMLIRM(dml_data_exp, ml_g, ml_m, n_folds = 10, score = 'ATTE', trimming_threshold = 0.025)
dml_irm_atte_exp.fit()<doubleml.double_ml_irm.DoubleMLIRM at 0x21ccbcb7050>np.random.seed(123)
dml_irm_atte_restricted = dml.DoubleMLIRM(dml_data_restricted, ml_g, ml_m, n_folds = 10, score = 'ATTE', trimming_threshold = 0.025)
dml_irm_atte_restricted.fit()<doubleml.double_ml_irm.DoubleMLIRM at 0x21ccbcefc10>results_irm_atte_df = pd.concat([dml_irm_atte_exp.summary, dml_irm_atte_restricted.summary], keys = ["Experimental", "Restricted"])
results_irm_atte_df.round(3)| coef | std err | t | P>|t| | 2.5 % | 97.5 % | ||
|---|---|---|---|---|---|---|---|
| Experimental | treatment | 1790.802 | 738.426 | 2.425 | 0.015 | 343.515 | 3238.090 |
| Restricted | treatment | 2752.281 | 825.913 | 3.332 | 0.001 | 1133.522 | 4371.041 |
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
colors = sns.color_palette()
plt.rcParams['figure.figsize'] = 10., 7.5
sns.set(font_scale=1.5)
sns.set_style('whitegrid', {'axes.spines.top': False,
'axes.spines.bottom': False,
'axes.spines.left': False,
'axes.spines.right': False})
plt.figure(figsize=(10, 15))
errors = np.full((2, results_irm_atte_df.shape[0]), np.nan)
errors[0, :] = results_irm_atte_df['coef'] - results_irm_atte_df['2.5 %']
errors[1, :] = results_irm_atte_df['97.5 %'] - results_irm_atte_df['coef']
plt.errorbar(['Experimental', 'Restricted'], results_irm_atte_df.coef, fmt='o', yerr=errors)
plt.title('Lalonde Data: IRM Estimates (ATTE)')
plt.ylabel('Coefficients and 95%-CI')
_ = plt.xlabel('Data Set')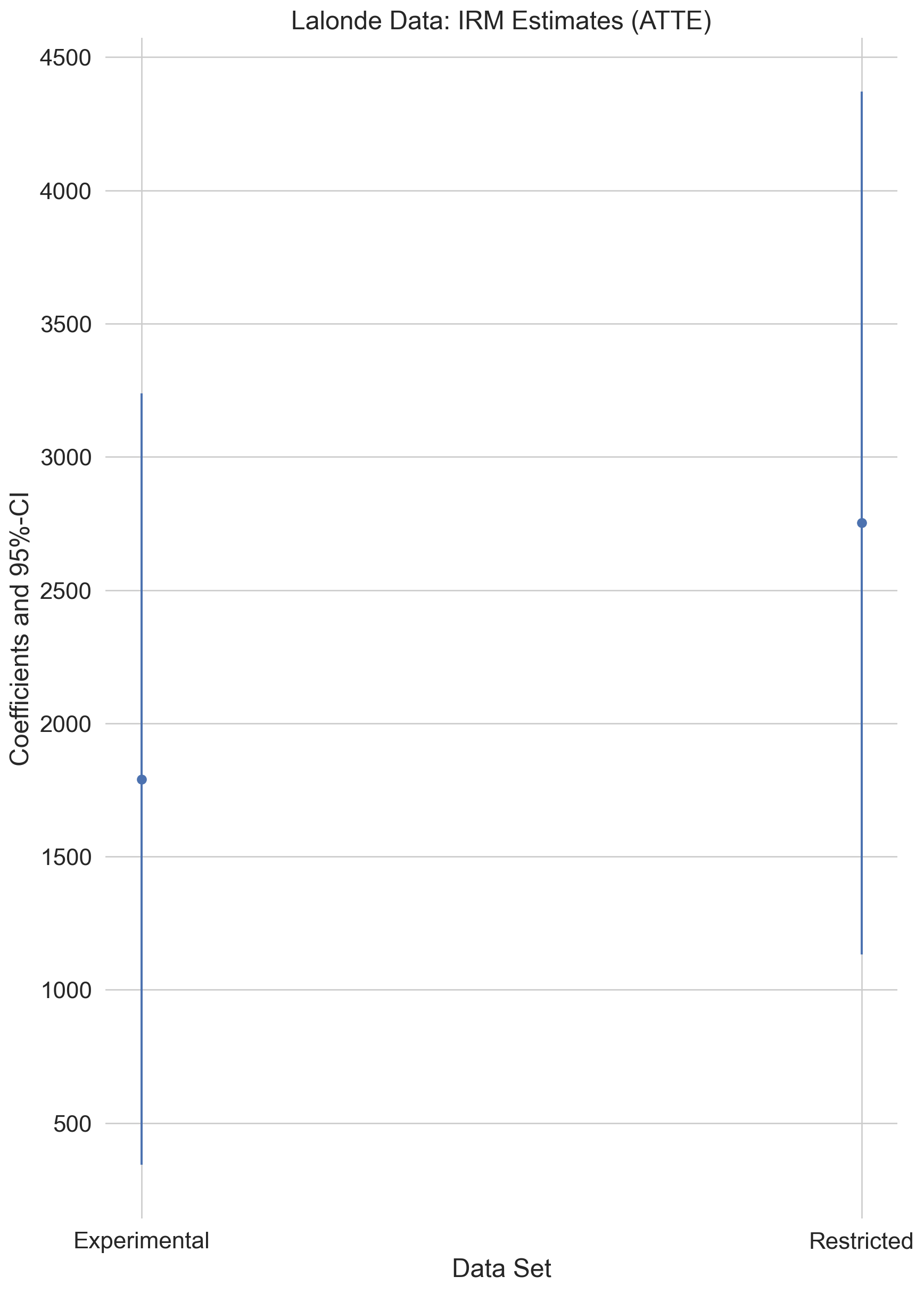
# ATE
dml_irm_ate_exp.sensitivity_analysis()
print(dml_irm_ate_exp.sensitivity_summary)
dml_irm_ate_restricted.sensitivity_analysis()
print(dml_irm_ate_restricted.sensitivity_summary)================== Sensitivity Analysis ==================
------------------ Scenario ------------------
Significance Level: level=0.95
Sensitivity parameters: cf_y=0.03; cf_d=0.03, rho=1.0
------------------ Bounds with CI ------------------
CI lower theta lower theta theta upper CI upper
treatment 81.115523 1245.293207 1676.151943 2107.01068 3230.468256
------------------ Robustness Values ------------------
H_0 RV (%) RVa (%)
treatment 0.0 11.168636 3.526529
================== Sensitivity Analysis ==================
------------------ Scenario ------------------
Significance Level: level=0.95
Sensitivity parameters: cf_y=0.03; cf_d=0.03, rho=1.0
------------------ Bounds with CI ------------------
CI lower theta lower theta theta upper CI upper
treatment 1915.26637 2949.293327 4173.360686 5397.428046 6628.249376
------------------ Robustness Values ------------------
H_0 RV (%) RVa (%)
treatment 0.0 9.859796 7.408799# ATTE
dml_irm_atte_exp.sensitivity_analysis()
print(dml_irm_atte_exp.sensitivity_summary)
dml_irm_atte_restricted.sensitivity_analysis()
print(dml_irm_atte_restricted.sensitivity_summary)================== Sensitivity Analysis ==================
------------------ Scenario ------------------
Significance Level: level=0.95
Sensitivity parameters: cf_y=0.03; cf_d=0.03, rho=1.0
------------------ Bounds with CI ------------------
CI lower theta lower theta theta upper CI upper
treatment 121.048443 1358.054458 1790.802261 2223.550064 3420.10178
------------------ Robustness Values ------------------
H_0 RV (%) RVa (%)
treatment 0.0 11.835759 3.77788
================== Sensitivity Analysis ==================
------------------ Scenario ------------------
Significance Level: level=0.95
Sensitivity parameters: cf_y=0.03; cf_d=0.03, rho=1.0
------------------ Bounds with CI ------------------
CI lower theta lower theta theta upper CI upper
treatment 421.485548 1854.179304 2752.281361 3650.383418 5138.154461
------------------ Robustness Values ------------------
H_0 RV (%) RVa (%)
treatment 0.0 8.909182 4.121919We consider the benchmark set of all pre-treatment income variables.
# All pre-treatment income variables
benchmark_set = ['RE74', 'RE75', 'pos74', 'pos75']
bench_irm_ate_exp = dml_irm_ate_exp.sensitivity_benchmark(benchmark_set)
bench_irm_ate_restricted = dml_irm_ate_restricted.sensitivity_benchmark(benchmark_set)
print(bench_irm_ate_restricted)
bench_irm_atte_exp = dml_irm_atte_exp.sensitivity_benchmark(benchmark_set)
print(bench_irm_atte_exp)
bench_irm_atte_restricted = dml_irm_atte_restricted.sensitivity_benchmark(benchmark_set)
print(bench_irm_atte_restricted)C:\Users\PuD\anaconda3\Lib\site-packages\doubleml\_utils_checks.py:204: UserWarning:
Propensity predictions from learner RandomForestClassifier(max_depth=5, random_state=42) for ml_m are close to zero or one (eps=1e-12).
C:\Users\PuD\anaconda3\Lib\site-packages\doubleml\_utils_checks.py:204: UserWarning:
Propensity predictions from learner RandomForestClassifier(max_depth=5, random_state=42) for ml_m are close to zero or one (eps=1e-12).
cf_y cf_d rho delta_theta
treatment 0.049217 0.0 -1.0 -719.317259
cf_y cf_d rho delta_theta
treatment 0.056706 0.160853 0.178883 225.272376
cf_y cf_d rho delta_theta
treatment 0.049217 0.121465 -1.0 -2167.62187# Utils to get benchmark dict
def make_bench_dict(pd_bench, name):
bench_dict = {'cf_d' : pd_bench['cf_d'].astype(float).round(3).tolist(),
'cf_y' : pd_bench['cf_y'].astype(float).round(3).tolist(),
'name' : [name]}
return bench_dictcontour_ate_exp = dml_irm_ate_exp.sensitivity_plot(grid_bounds = (0.25, 0.25), benchmarks = make_bench_dict(bench_irm_ate_exp, 'Pre Income'))
contour_ate_exp.show()
print(bench_irm_ate_exp) cf_y cf_d rho delta_theta
treatment 0.056706 0.049085 -0.072664 -52.942508contour_ate_restricted = dml_irm_ate_restricted.sensitivity_plot(grid_bounds = (0.25, 0.25), benchmarks = make_bench_dict(bench_irm_ate_restricted, 'Pre Income'))
contour_ate_restricted.show()
print(bench_irm_ate_restricted) cf_y cf_d rho delta_theta
treatment 0.049217 0.0 -1.0 -719.317259contour_atte_exp = dml_irm_atte_exp.sensitivity_plot(grid_bounds = (0.25, 0.25), benchmarks = make_bench_dict(bench_irm_atte_exp, 'Pre Income'))
contour_atte_exp.show()
print(bench_irm_atte_exp) cf_y cf_d rho delta_theta
treatment 0.056706 0.160853 0.178883 225.272376contour_atte_restricted = dml_irm_atte_restricted.sensitivity_plot(grid_bounds = (0.25, 0.25), benchmarks = make_bench_dict(bench_irm_atte_restricted, 'Pre Income'))
contour_atte_restricted.show()
print(bench_irm_atte_restricted) cf_y cf_d rho delta_theta
treatment 0.049217 0.121465 -1.0 -2167.62187bias_value = 1000
H0_ate_exp = dml_irm_ate_exp.coef - bias_value
H0_ate_restricted = dml_irm_ate_restricted.coef - bias_value
# ATE
dml_irm_ate_exp.sensitivity_analysis(null_hypothesis = H0_ate_exp)
print(dml_irm_ate_exp.sensitivity_summary)
dml_irm_ate_restricted.sensitivity_analysis(null_hypothesis = H0_ate_restricted)
print(dml_irm_ate_restricted.sensitivity_summary)================== Sensitivity Analysis ==================
------------------ Scenario ------------------
Significance Level: level=0.95
Sensitivity parameters: cf_y=0.03; cf_d=0.03, rho=1.0
------------------ Bounds with CI ------------------
CI lower theta lower theta theta upper CI upper
treatment 81.115523 1245.293207 1676.151943 2107.01068 3230.468256
------------------ Robustness Values ------------------
H_0 RV (%) RVa (%)
treatment 676.151943 6.824217 0.000489
================== Sensitivity Analysis ==================
------------------ Scenario ------------------
Significance Level: level=0.95
Sensitivity parameters: cf_y=0.03; cf_d=0.03, rho=1.0
------------------ Bounds with CI ------------------
CI lower theta lower theta theta upper CI upper
treatment 1915.26637 2949.293327 4173.360686 5397.428046 6628.249376
------------------ Robustness Values ------------------
H_0 RV (%) RVa (%)
treatment 3173.360686 2.45777 0.000403# ATTE
H0_atte_exp = dml_irm_atte_exp.coef - bias_value
H0_atte_restricted = dml_irm_atte_restricted.coef - bias_value
dml_irm_atte_exp.sensitivity_analysis(null_hypothesis = H0_atte_exp)
print(dml_irm_atte_exp.sensitivity_summary)
dml_irm_atte_restricted.sensitivity_analysis(null_hypothesis = H0_atte_restricted)
print(dml_irm_atte_restricted.sensitivity_summary)================== Sensitivity Analysis ==================
------------------ Scenario ------------------
Significance Level: level=0.95
Sensitivity parameters: cf_y=0.03; cf_d=0.03, rho=1.0
------------------ Bounds with CI ------------------
CI lower theta lower theta theta upper CI upper
treatment 121.048443 1358.054458 1790.802261 2223.550064 3420.10178
------------------ Robustness Values ------------------
H_0 RV (%) RVa (%)
treatment 790.802261 6.795475 0.000446
================== Sensitivity Analysis ==================
------------------ Scenario ------------------
Significance Level: level=0.95
Sensitivity parameters: cf_y=0.03; cf_d=0.03, rho=1.0
------------------ Bounds with CI ------------------
CI lower theta lower theta theta upper CI upper
treatment 421.485548 1854.179304 2752.281361 3650.383418 5138.154461
------------------ Robustness Values ------------------
H_0 RV (%) RVa (%)
treatment 1752.281361 3.33467 0.000461We consider the benchmark set of all pre-treatment income variables.
# All pre-treatment income variables
benchmark_set = ['RE74', 'RE75', 'pos74', 'pos75']
bench_irm_ate_exp = dml_irm_ate_exp.sensitivity_benchmark(benchmark_set)
bench_irm_ate_restricted = dml_irm_ate_restricted.sensitivity_benchmark(benchmark_set)
print(bench_irm_ate_restricted)
bench_irm_atte_exp = dml_irm_atte_exp.sensitivity_benchmark(benchmark_set)
print(bench_irm_atte_exp)
bench_irm_atte_restricted = dml_irm_atte_restricted.sensitivity_benchmark(benchmark_set)
print(bench_irm_atte_restricted)C:\Users\PuD\anaconda3\Lib\site-packages\doubleml\_utils_checks.py:204: UserWarning:
Propensity predictions from learner RandomForestClassifier(max_depth=5, random_state=42) for ml_m are close to zero or one (eps=1e-12).
C:\Users\PuD\anaconda3\Lib\site-packages\doubleml\_utils_checks.py:204: UserWarning:
Propensity predictions from learner RandomForestClassifier(max_depth=5, random_state=42) for ml_m are close to zero or one (eps=1e-12).
cf_y cf_d rho delta_theta
treatment 0.049217 0.0 -1.0 -719.317259
cf_y cf_d rho delta_theta
treatment 0.056706 0.160853 0.178883 225.272376
cf_y cf_d rho delta_theta
treatment 0.049217 0.121465 -1.0 -2167.62187contour_ate_exp = dml_irm_ate_exp.sensitivity_plot(grid_bounds = (0.25, 0.25), benchmarks = make_bench_dict(bench_irm_ate_exp, 'Pre Income'))
contour_ate_exp.show()
print(bench_irm_ate_exp) cf_y cf_d rho delta_theta
treatment 0.056706 0.049085 -0.072664 -52.942508contour_ate_restricted = dml_irm_ate_restricted.sensitivity_plot(grid_bounds = (0.25, 0.25), benchmarks = make_bench_dict(bench_irm_ate_restricted, 'Pre Income'))
contour_ate_restricted.show()
print(bench_irm_ate_restricted) cf_y cf_d rho delta_theta
treatment 0.049217 0.0 -1.0 -719.317259contour_atte_exp = dml_irm_atte_exp.sensitivity_plot(grid_bounds = (0.25, 0.25), benchmarks = make_bench_dict(bench_irm_atte_exp, 'Pre Income'))
contour_atte_exp.show()
print(bench_irm_atte_exp) cf_y cf_d rho delta_theta
treatment 0.056706 0.160853 0.178883 225.272376contour_atte_restricted = dml_irm_atte_restricted.sensitivity_plot(grid_bounds = (0.25, 0.25), benchmarks = make_bench_dict(bench_irm_atte_restricted, 'Pre Income'))
contour_atte_restricted.show()
print(bench_irm_atte_restricted) cf_y cf_d rho delta_theta
treatment 0.049217 0.121465 -1.0 -2167.62187This scenario is considered as the causal effect estimates obtained for different samples have different signs.↩︎