| coef | std err | t | P>|t| | 2.5 % | 97.5 % | |
|---|---|---|---|---|---|---|
| e401 | 8121.565 | 1106.553 | 7.34 | 0.0 | 5952.76 | 10290.369 |
DoubleML - Sensitivity Analysis
Tools for Causality
Grenoble, Sept 25 - 29, 2023
Philipp Bach, Sven Klaassen
Motivation
- Whenever we have (properly collected) experimental data, we have good reason to believe that the independence assumption holds, i.e., the treatment assignment is independent of the potential outcomes
\[ Y(d) ⊥ D \]
- However, what about causal evidence from observational data? 😱
Motivation
Observational studies are often based on the assumption of conditional independence1
Conditional on pre-treatment confounders \(X\), the treatment is as good as randomly assigned
\[ Y(d) ⊥ D \mid X \]
- In general, the independence assumption is not testable!
Code
import networkx as nx
import matplotlib.pyplot as plt
G = nx.DiGraph()
# Add nodes
G.add_node("D")
G.add_node("Y")
G.add_node("X")
G.add_edge("D", "Y")
G.add_edge("X", "Y")
G.add_edge("X", "D")
# Draw the graph
plt.figure(figsize=(4, 3))
pos = {"D": (0, 0), "Y": (2, 0), "X": (1,1)}
edge_colors = ['black', 'black', 'black']
nx.draw(G, pos, with_labels=True, node_size=800, node_color='lightblue',
edge_color=edge_colors)
plt.show()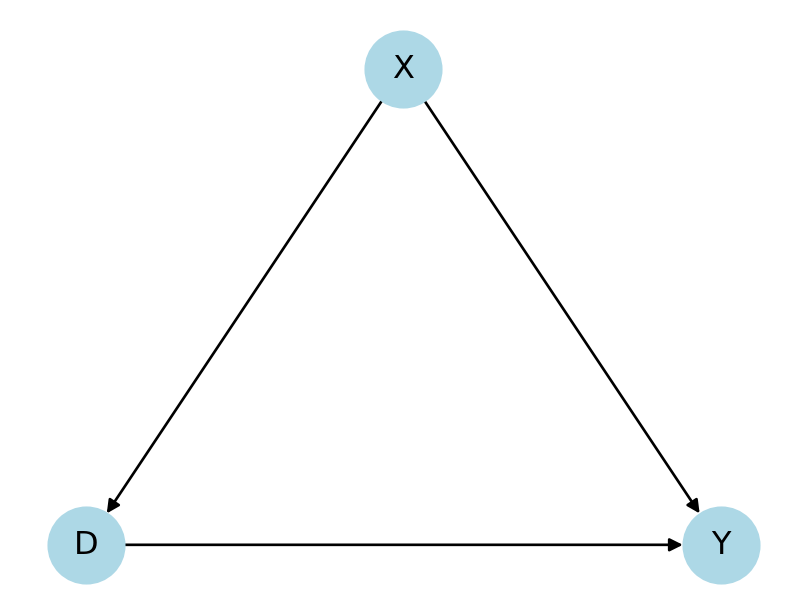
Motivation
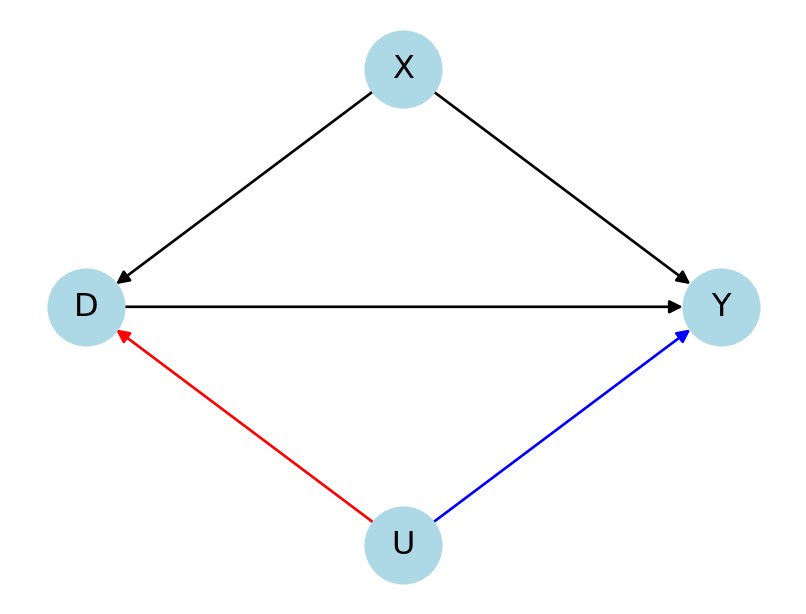
What if the conditional independence assumption is violated?
Unobserved confounders U would introduce an omitted variable bias/ selection-into-treatment bias
Key questions:
- How strong would a confounding relationship need to be in order to change the conclusions of our analysis?
- Would such a confounding relationship be plausibly present in our data?
Code
import networkx as nx
import matplotlib.pyplot as plt
G = nx.DiGraph()
# Add nodes
G.add_node("D")
G.add_node("Y")
G.add_node("X")
G.add_node("U")
G.add_edge("D", "Y")
G.add_edge("X", "Y")
G.add_edge("X", "D")
G.add_edge("U", "D")
G.add_edge("U", "Y")
# Draw the graph
plt.figure(figsize=(4, 3))
pos = {"D": (0, 0), "Y": (2, 0), "X": (1,1), "U": (1,-1)}
edge_colors = ['black', 'black', 'black', 'red', 'blue']
nx.draw(G, pos, with_labels=True, node_size=800, node_color='lightblue',
edge_color=edge_colors)
plt.show()
Outlook: Sensitivity Analysis
- How strong would a confounding relationship need to be in order to change the conclusions of our analysis?
- Model the strength of the confounding relationships in terms of some sensitivity parameters, i.e.,
- \(U\) \(\rightarrow\) \(D\) and
- \(U\) \(\rightarrow\) \(Y\)
- Would such a confounding relationship be plausibly present in our data?
- Benchmarking framework
Code
import networkx as nx
import matplotlib.pyplot as plt
G = nx.DiGraph()
# Add nodes
G.add_node("D")
G.add_node("Y")
G.add_node("X")
G.add_node("U")
G.add_edge("D", "Y")
G.add_edge("X", "Y")
G.add_edge("X", "D")
G.add_edge("U", "D")
G.add_edge("U", "Y")
# Draw the graph
plt.figure(figsize=(4, 3))
pos = {"D": (0, 0), "Y": (2, 0), "X": (1,1), "U": (1,-1)}
edge_colors = ['black', 'black', 'black', 'red', 'blue']
nx.draw(G, pos, with_labels=True, node_size=800, node_color='lightblue',
edge_color=edge_colors)
plt.show()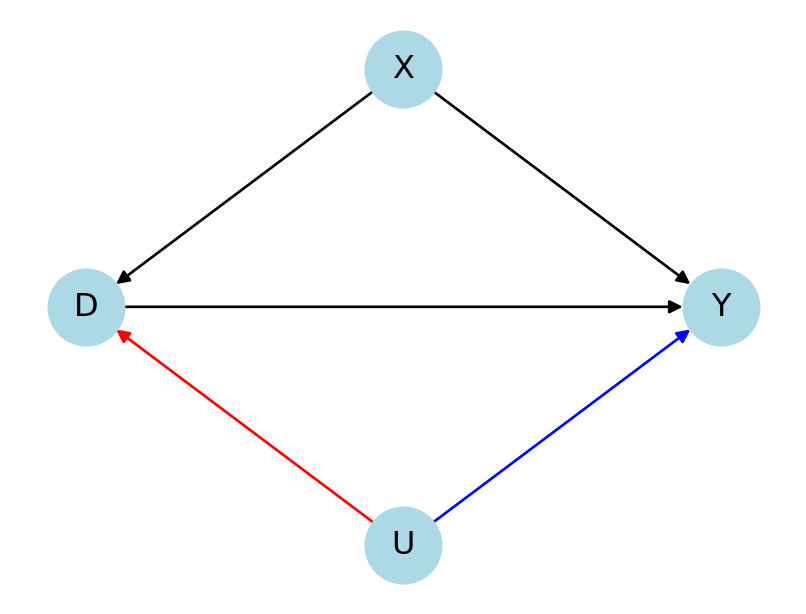
Example: Linear Regression Model
Sensitivity parameters in Cinelli and Hazlett (2020)
\(U\) \(\rightarrow\) \(D\): Share of residual variation of \(D\) explained by omitted confounder(s) \(U\), after taking \(X\) into account, \(R^2_{D\sim U|X}\)
\(U\) \(\rightarrow\) \(Y\): Share of residual variation of \(Y\) explained by \(U\), after taking \(X\) and \(D\) into account, \(R^2_{Y\sim U|D,X}\)
Code
import networkx as nx
import matplotlib.pyplot as plt
G = nx.DiGraph()
# Add nodes
G.add_node("D")
G.add_node("Y")
G.add_node("X")
G.add_node("U")
G.add_edge("D", "Y")
G.add_edge("X", "Y")
G.add_edge("X", "D")
G.add_edge("U", "D")
G.add_edge("U", "Y")
# Draw the graph
plt.figure(figsize=(4, 3))
pos = {"D": (0, 0), "Y": (2, 0), "X": (1,1), "U": (1,-1)}
edge_colors = ['black', 'black', 'black', 'red', 'blue']
nx.draw(G, pos, with_labels=True, node_size=800, node_color='lightblue',
edge_color=edge_colors)
plt.show()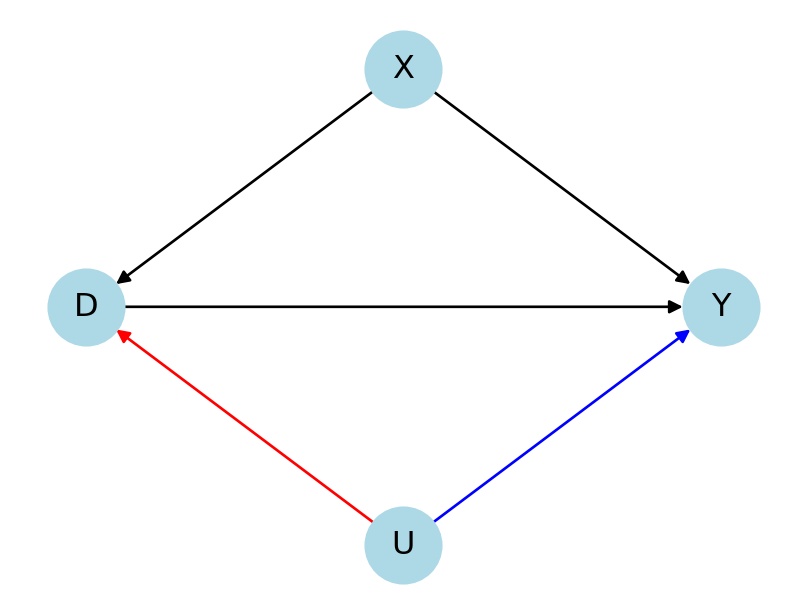
Example: Linear Regression Model
Results in Cinelli and Hazlett (2020)
Bounds for the omitted variable bias \(\theta_{0,s} - \theta_{0}\) and confidence intervals as based on values for these sensitivity parameters
Various measures to be reported:
- Robustness value
- Extreme scenarios
Visualization:
- Contour plots (Imbens 2003)
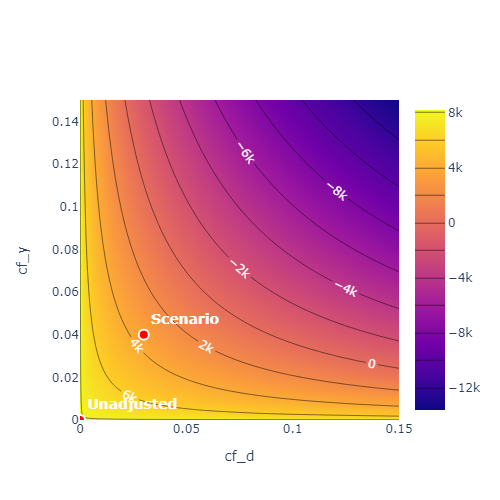
Sensitivity Analysis in DoubleML
- At given values for the sensitivity parameters
cf_dandcf_y, we can compute bounds for- The parameter \(\theta_0\) and
- \((1-\alpha)\) confidence intervals
- The interpretation of the sensitivity parameters depends on the causal model
PLR
- \(U\) \(\rightarrow\) \(D\): Partial nonparametric \(R^2\) of \(U\) with \(D\), given \(X\)
- \(U\) \(\rightarrow\) \(Y\): Partial nonparametric \(R^2\) of \(U\) with \(Y\), given \(D\) and \(X\)
Code
import networkx as nx
import matplotlib.pyplot as plt
G = nx.DiGraph()
# Add nodes
G.add_node("D")
G.add_node("Y")
G.add_node("X")
G.add_node("U")
G.add_edge("D", "Y")
G.add_edge("X", "Y")
G.add_edge("X", "D")
G.add_edge("U", "D")
G.add_edge("U", "Y")
# Draw the graph
plt.figure(figsize=(4, 3))
pos = {"D": (0, 0), "Y": (2, 0), "X": (1,1), "U": (1,-1)}
edge_colors = ['black', 'black', 'black', 'red', 'blue']
nx.draw(G, pos, with_labels=True, node_size=800, node_color='lightblue',
edge_color=edge_colors)
plt.show()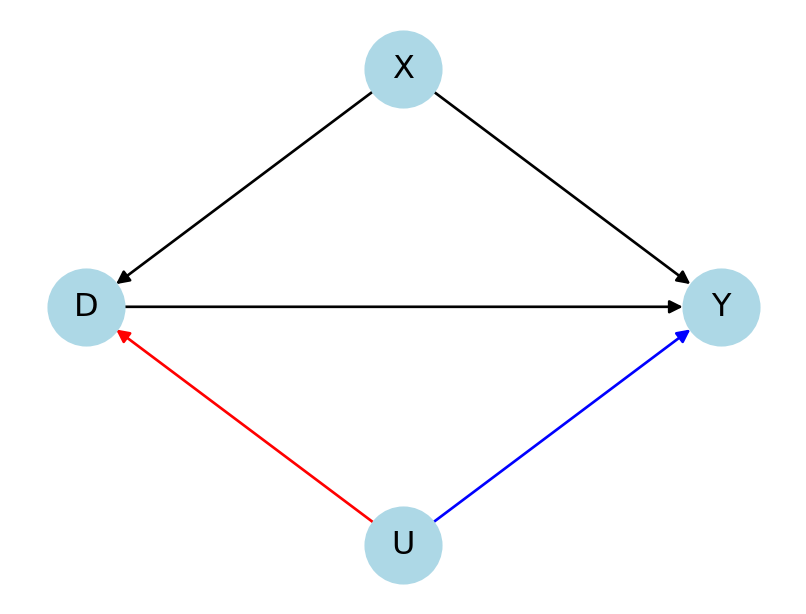
Sensitivity Analysis in DoubleML
- At given values for the sensitivity parameters
cf_dandcf_y, we can compute bounds for- The parameter \(\theta_0\) and
- \((1-\alpha)\) confidence intervals
- The interpretation of the sensitivity parameters depends on the causal model
IRM
- \(U\) \(\rightarrow\) \(D\): Average gain in quality to predict \(D\) by using \(U\) in addition to \(X\) (relative)
- \(U\) \(\rightarrow\) \(Y\): Partial nonparametric \(R^2\) of \(U\) with \(Y\), given \(D\) and \(X\)
Code
import networkx as nx
import matplotlib.pyplot as plt
G = nx.DiGraph()
# Add nodes
G.add_node("D")
G.add_node("Y")
G.add_node("X")
G.add_node("U")
G.add_edge("D", "Y")
G.add_edge("X", "Y")
G.add_edge("X", "D")
G.add_edge("U", "D")
G.add_edge("U", "Y")
# Draw the graph
plt.figure(figsize=(4, 3))
pos = {"D": (0, 0), "Y": (2, 0), "X": (1,1), "U": (1,-1)}
edge_colors = ['black', 'black', 'black', 'red', 'blue']
nx.draw(G, pos, with_labels=True, node_size=800, node_color='lightblue',
edge_color=edge_colors)
plt.show()