Bach, Philipp, Victor Chernozhukov, Malte S Kurz, and Martin Spindler. 2022. “DoubleML-an Object-Oriented Implementation of Double Machine Learning in Python.” Journal of Machine Learning Research 23: 53–51.
Bach, Philipp, Victor Chernozhukov, Malte S Kurz, Martin Spindler, and Sven Klaassen. 2021.
“DoubleML – An Object-Oriented Implementation of Double Machine Learning in R.” https://arxiv.org/abs/2103.09603.
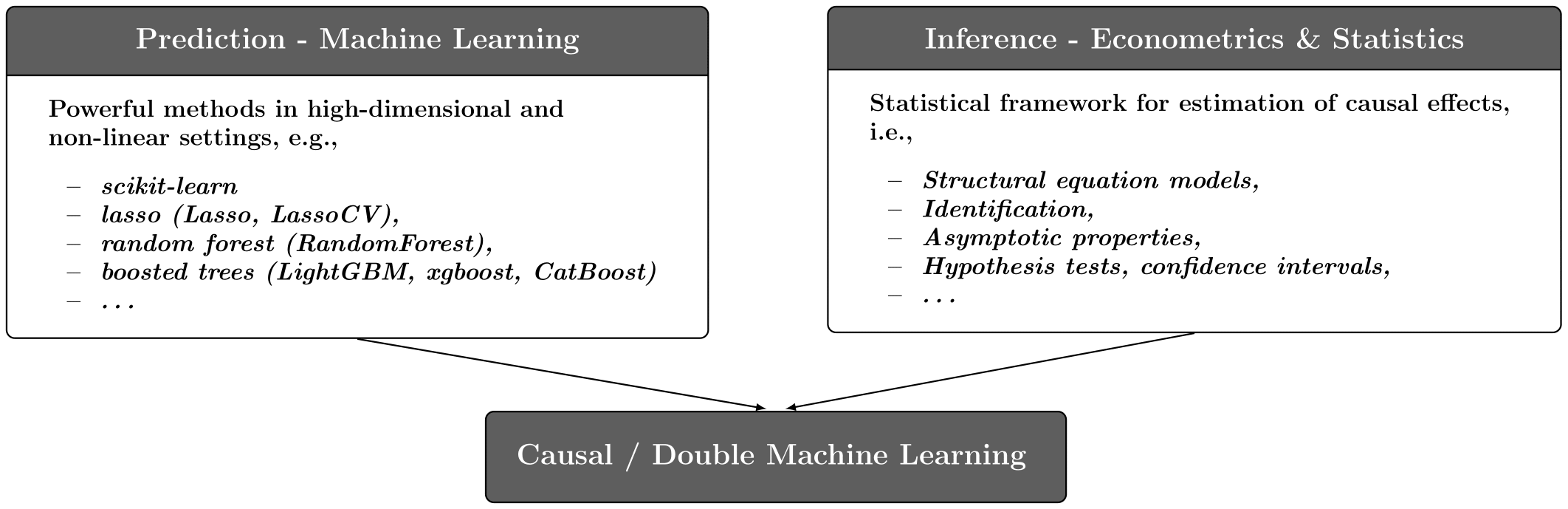
Chernozhukov, Victor, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. 2018.
“Double/Debiased Machine Learning for Treatment and Structural Parameters.” The Econometrics Journal 21 (1): C1–68.
https://onlinelibrary.wiley.com/doi/abs/10.1111/ectj.12097.
Chernozhukov, Victor, Christian Hansen, Nathan Kallus, Martin Spindler, and Vasilis Syrgkanis. forthcoming. Applied Causal Inference Powered by ML and AI. online.
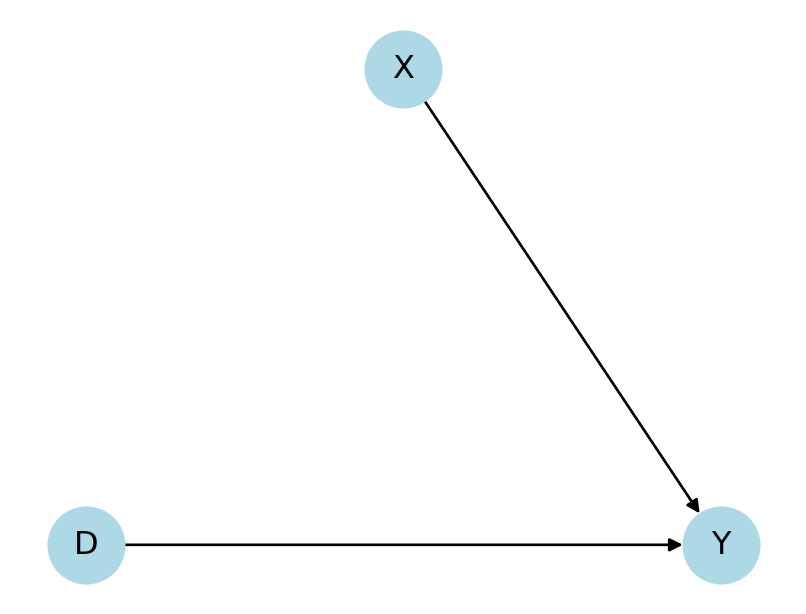
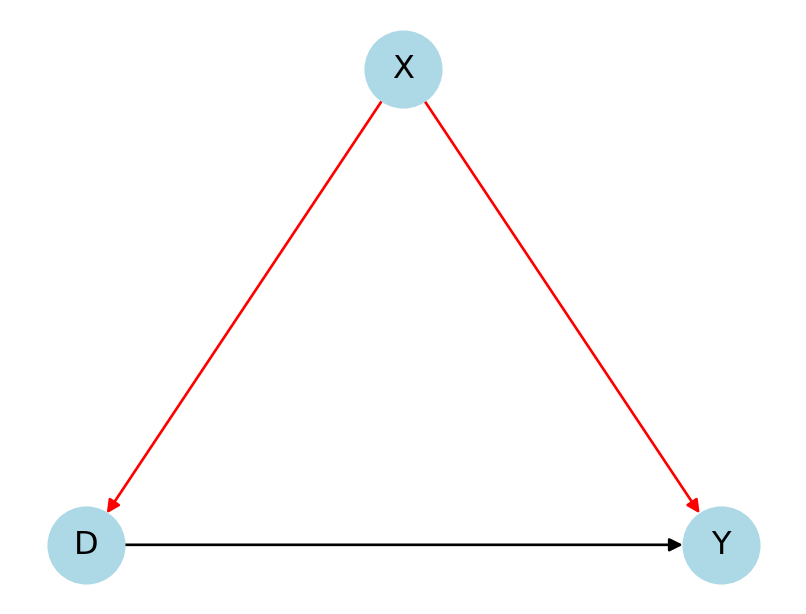
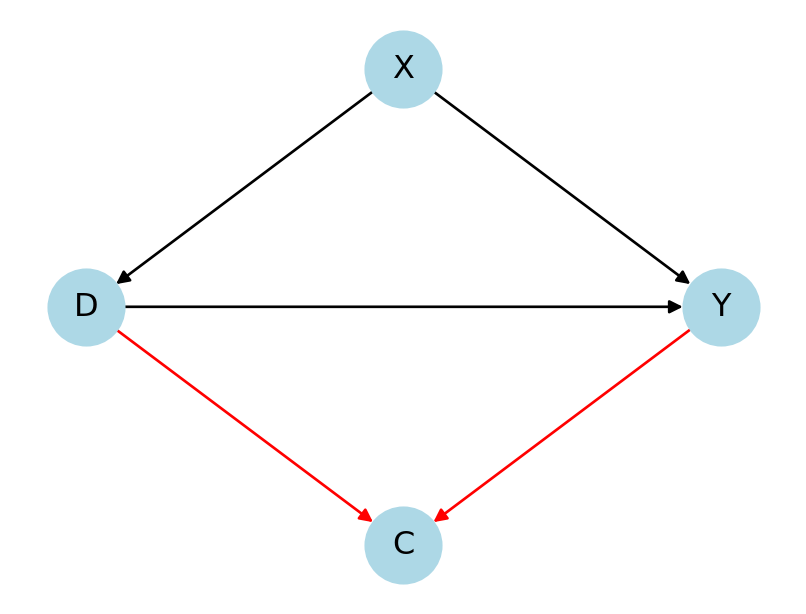
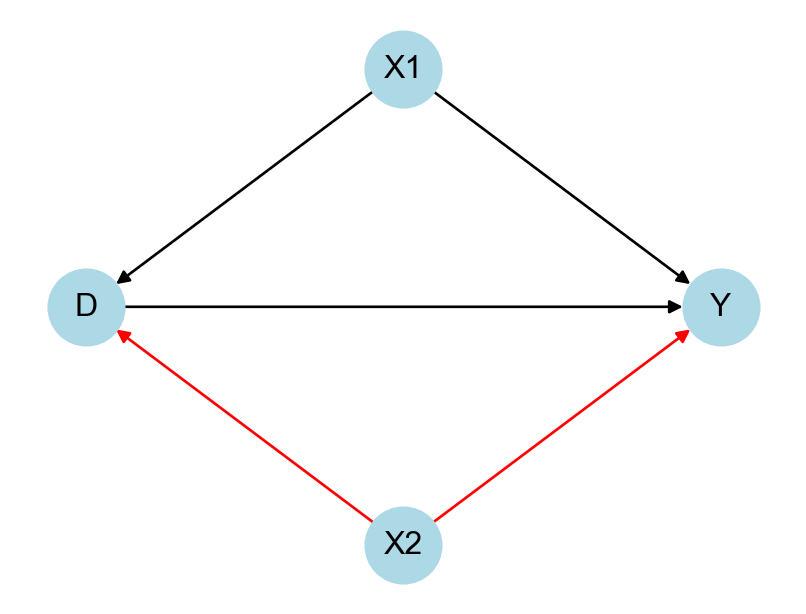
Cinelli, Carlos, Andrew Forney, and Judea Pearl. 2022. “A Crash Course in Good and Bad Controls.” Sociological Methods & Research, 00491241221099552.
Facure, Matheus, and Michell Germano. 2021.
“matheusfacure/python-causality-handbook: First Edition.” Zenodo.
https://doi.org/10.5281/zenodo.4445778.
Glymour, Madelyn, Judea Pearl, and Nicholas P Jewell. 2016. Causal Inference in Statistics: A Primer. John Wiley & Sons.
Huber, Martin. 2023. Causal Analysis: Impact Evaluation and Causal Machine Learning with Applications in r. MIT Press.